ISCA作为体系结构领域的顶级会议,一直是全球体系结构研究的风向标。本届ISCA 2025在近期召开,会议主议程为期三天,共设置28个session,内容广泛,既包括热点方向,也涵盖基础领域。
从议题分布可以看出,本次ISCA不仅在大模型(LLM)、机器学习加速器(ML Accelerator)、量子计算(Quantum)、加密(Crypto)等热点问题上成果丰富,也关注从微结构到访存、互联,从系统设计到数据中心架构等体系结构研究的核心方向,反映出该领域研究的深度和广度。
本次会议评选出了两篇Best Paper,来自剑桥大学的“Precise Exceptions in Relaxed Architectures”和北京大学的“H2-LLM: Hardware-Dataflow Co-Exploration for Heterogeneous Hybrid-Bonding-Based Low-Batch LLM Inference” 荣获最佳论文奖。这两篇论文恰好代表了ISCA长期重视的两类研究方向:一是围绕体系结构基础问题的深度研究,二是面向新兴需求的系统化软硬件协同优化和探索。
由于体系结构基础问题已经深耕数十年,新的题目有限,近几年的ISCA上,面向新场景(如AI大模型)的系统化研究逐渐成为主流。这类研究通常具备几个共同特点:针对实际场景的新挑战,借助最新芯片工艺或封装集成技术,探索软硬件协同设计空间,解决高价值、高复杂度的问题。也正因此,能够被ISCA接收的论文通常不仅具备创新性,也需要完成从理论到设计到验证的完整链条,并与现有最佳工作进行全面对比。ISCA的论文对于理解和把握各研究方向的发展脉络和最新趋势,提供了极具价值的参考。
DeepSeek对AI大模型计算系统的优化建议
如何满足AI大模型的计算需求无疑是当前体系结构研究的最重要的研究方向。值得注意的是,本次会议的Industry track中有一篇来自DeepSeek的文章:Insights into DeepSeek-V3: Scaling Challenges and Reflections on Hardware for AI Architectures,阐述了在大模型训练和部署第一线的团队看到的挑战以及解决的思路,同时还给出了优化芯片和软硬件系统的建议。
这些建议整理一下可以分为如下几个方面:
系统架构选择
· 采用稀疏模型(如MoE)以减少计算和通信开销;
· 节点内(Scale-Up)和节点间(Scale-Out)通信统一融合设计,并设计相应的NIC或I/O Die;
· 集成专用通信协处理器,卸载GPU通信负担;
· 智能NIC(包括一定交换功能)集成到I/O Die;
· CPU-GPU在scale-up域中直接互连;
· 探索晶圆级集成架构(如Wafer-Scale Engine)提高单芯片算力与存储密度。
定制设计
· 改进Tensor Core,支持细粒度量化和低精度(可定制)计算,以及高精度(FP32)累加;
· 内置数据压缩解压引擎,减少通信带宽;
· 细粒度硬件同步机制;
· 增强系统可靠性的错误校正与监测电路。
访存优化
· 广泛应用FP8等低精度数据格式,降低内存占用;
· 注意力机制的KV缓存压缩(如MLA多头潜在注意力机制);
· 使用3D堆叠存储技术,实现更高的带宽与更低延迟。
网络和通信优化
· 采用光电融合互连技术(如CPO),提高可扩展性并降低能耗;
· 无损网络,自适应路由,高效容错协议,动态资源管理;
· 在网计算和压缩,网络设备内直接进行部分计算和数据压缩处理;
· 硬件支持内存语义通信有序性。
这些内容可以说是大模型公司对于未来智能计算系统的直接需求,本次会议中也有不少工作已经在做相应的探索。另一方面,很多需求只是指出了大的方向,还有很多细节的工作要做,可以说是给了大家不少研究机会。
AI计算系统相关论文讨论
在ISCA会议的研究工作中,我们比较关心AI相关的工作,下面挑选几篇论文进行讨论。篇幅所限,主要简介这些工作试图解决的问题和做出的主要贡献供大家参考,感兴趣的读者建议进一步阅读原文。
系统级软硬件协同优化和设计空间探索
首先我们来看几篇进行系统级软硬件协同优化的工作。
WSC-LLM: Efficient LLM Service and Architecture Co-exploration for Wafer-scale Chips
这篇论文关注晶圆级芯片(WSC)上大模型推理服务的高效部署,通过体系结构与调度策略的协同探索来充分发挥晶圆级集成的潜力。晶圆级芯片将多颗裸片高密度集成并通过高速晶圆内互连连接,在提供超大规模算力的同时,需要在有限的晶圆面积内权衡计算核心、存储容量和通信带宽的分配。由于提供的更高的计算和存储密度,这种技术有很大潜力,但除了WSC实现的工程难度外,Compute-Storage-Communication资源的平衡配置和动态的负载调度成为其支持LLM推理服务的关键挑战。
我们知道,LLM推理本身包含预填充(Prefill)和解码(Decode)两个阶段:预填充阶段需一次性处理全部输入上下文,计算密集;解码阶段逐token生成,内存和通信开销占主导。这两个阶段资源需求差异巨大,这个是目前很多大模型优化工作重点关注的问题。
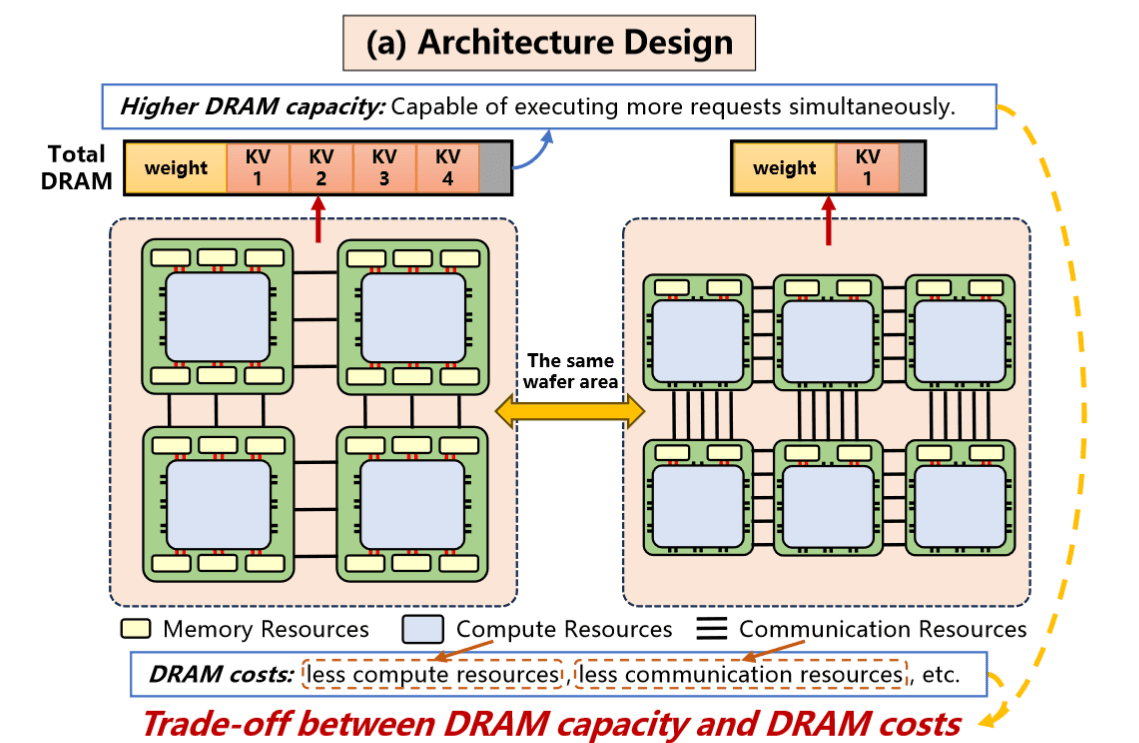
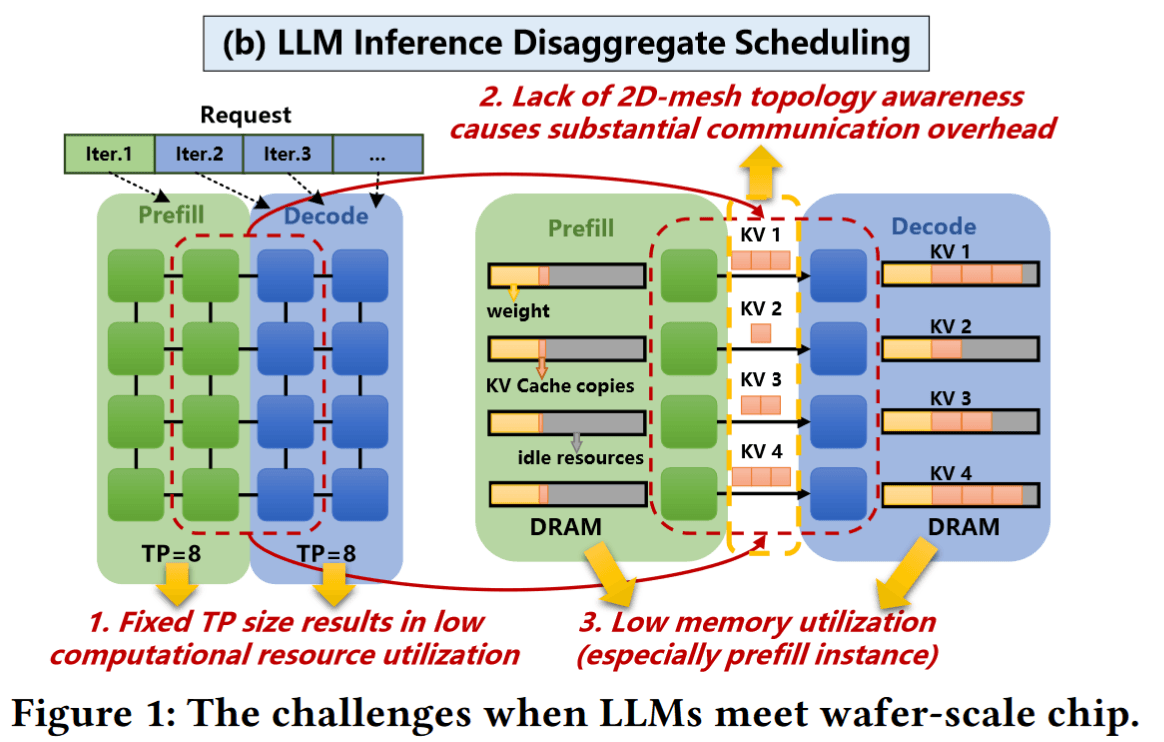
WSC-LLM提出了一个架构与调度联合探索框架。
首先,作者定义了一个高度可配置的晶圆级硬件模板,包含可调节的计算阵列规模、片上存储、互连拓扑等参数,用于表示各种可能的晶圆芯片架构。借助该模板,WSC-LLM 使用设计空间搜索来寻找在晶圆面积约束下计算、存储、通信资源的最优配比。
其次,在调度层面,框架充分利用晶圆级芯片超高的裸片间带宽和细粒度并行能力,探索分离式调度策略:将预填充和解码阶段的执行相互解耦,在晶圆上划分不同分组分别部署针对两个阶段优化的并行执行方案。例如,不同阶段各自采用特定的张量并行度、模型分片和内存管理策略,以匹配各自的负载特性。
此外,WSC-LLM提出了针对Wafer 2D网格互连特点的优化方法,以减少不同阶段切换时KV cache传输的延迟,并协调多个分组间的内存共享以提高KV存储利用率。通过在架构和调度两个维度同时搜索,WSC-LLM 找到了显著优于既有方案的设计点。与目前业界大型模型推理系统相比,该框架使性能平均提升三倍以上。更重要的是,借助WSC-LLM的联合探索,作者获得了一系列关于晶圆级LLM系统设计的启示:例如,在晶圆级芯片上为LLM服务时,适中的DRAM容量配置可在算力、存储和通信之间达到最佳平衡;又如,仅提高内存带宽不足以满足高效推理需求,还需匹配足够的片间通信能力以及高效的内存管理策略。
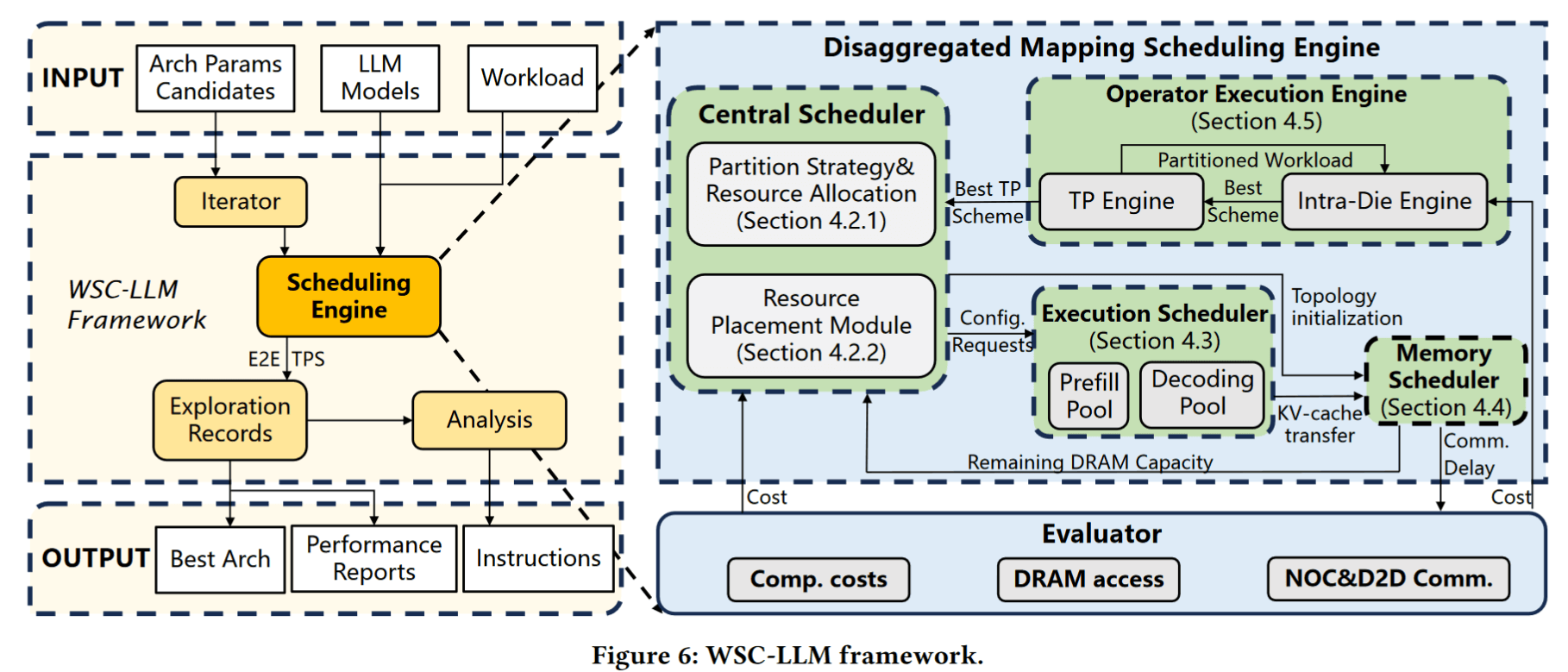
Hybe: GPU-NPU Hybrid System for Efficient LLM Inference with Million-Token Context Window
这篇文章针对超长上下文大型语言模型(支持百万级token上下文)推理的硬件低效难题,提出了一种GPU与NPU协同的异构推理系统。实际上,这篇论文希望解决的问题仍然是,LLM推理中prefill和decode两个阶段计算模式存在巨大差异的问题,而这个问题会随着上下文窗口的扩展更为严重。
针对这一问题,目前主要的解决方案是PD分离方法,即在不同阶段配置不同的资源,甚至不同配置的GPU芯片。这篇文章更近一步,采用GPU+NPU混合架构:利用现有高性能GPU执行预填充阶段的大矩阵计算,同时引入定制的轻量级NPU(神经处理单元)专门负责解码阶段。该NPU仅包含满足内存带宽充分利用所需的计算资源,其数据流架构经过优化,可在解码这种以内存访存为主的任务中实现更高的内存带宽利用率和计算单元利用率,显著提高硬件效率。
此外,Hybe的工作还包括细粒度的KV cache传输与调度机制,分阶段流水调度,尽可能缓解KV cache的存储压力,并让GPU和NPU交替处于工作状态,减少空闲停顿。当然,这些优化在目前大模型inference serving中算是常规操作。因此,这个工作最重要还是GPU+NPU这个架构选择。
UGPU: Dynamically Constructing Unbalanced GPUs for Enhanced Resource Efficiency
UGPU 给解决上述计算需求不一致的情况给出了另外一种思路:能否动态调整GPU的资源配置,使其能够同时支持不同roofline模式的workload呢?
传统GPU硬件在设计时保持计算单元(SM)与内存带宽/通道数量的大致固定比例(roofline),即“均衡”配置,以适配通用场景,而每款GPU芯片的roofline是确定的。如果应用场景需要的workload roofline和芯片的配置,则会导致资源浪费。
比如,计算密集(compute-bound)型任务难以耗尽内存带宽,而内存密集(memory-bound)型任务的SM计算单元大量空闲,甚至还有IO-bound的情况。前面已经看到,LLM inference的特点,就是一个应用里面存在prefill/decode两个roofline不同的情况。UGPU的思路是在单颗物理GPU上动态划分出多个虚拟GPU切片(slices),按需给予不同应用不对称的SM和内存通道资源配额,从而使计算型任务和内存型任务各自“扬长避短”,提高整体资源利用率和性能(如下图所示)。
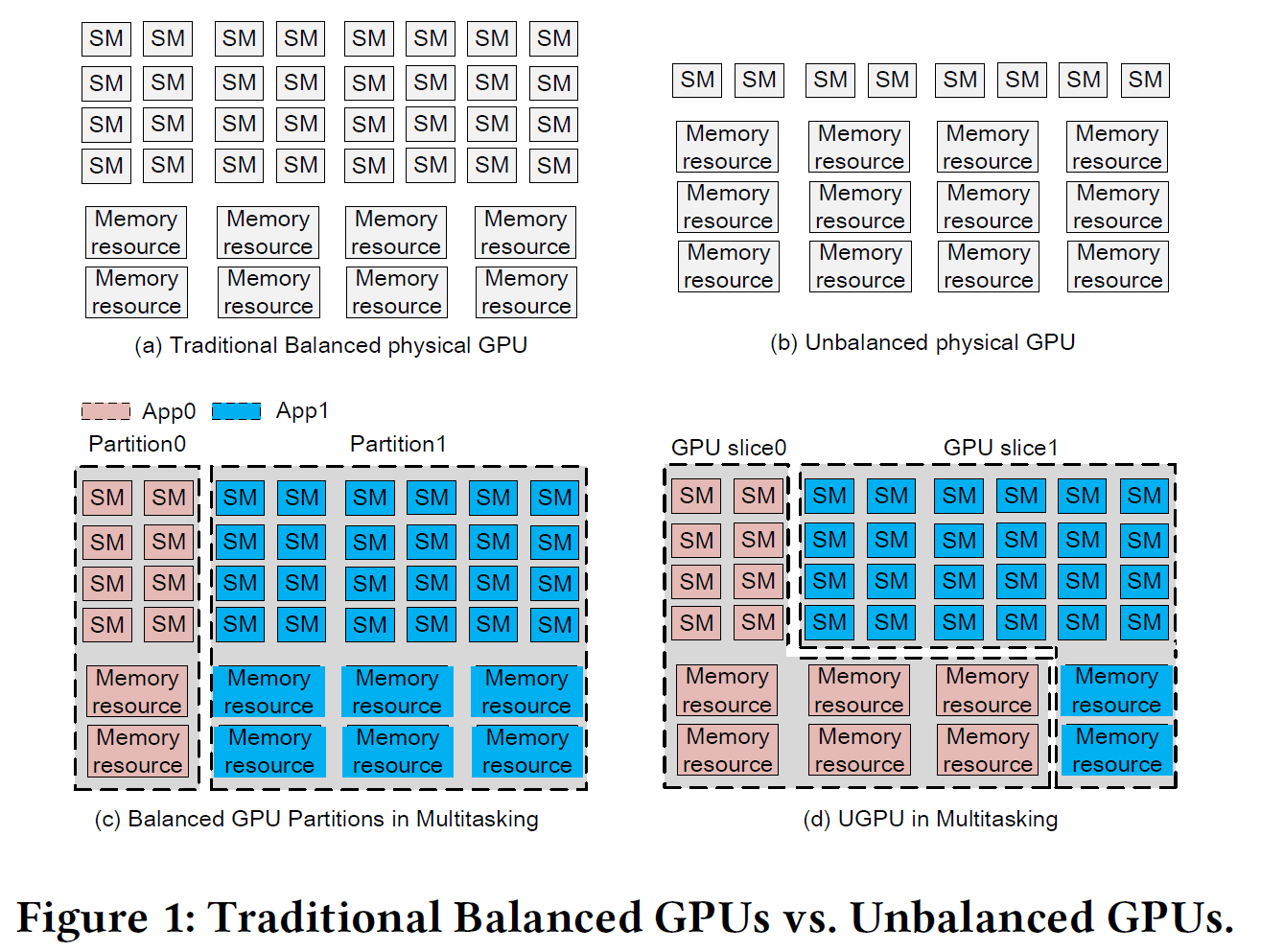
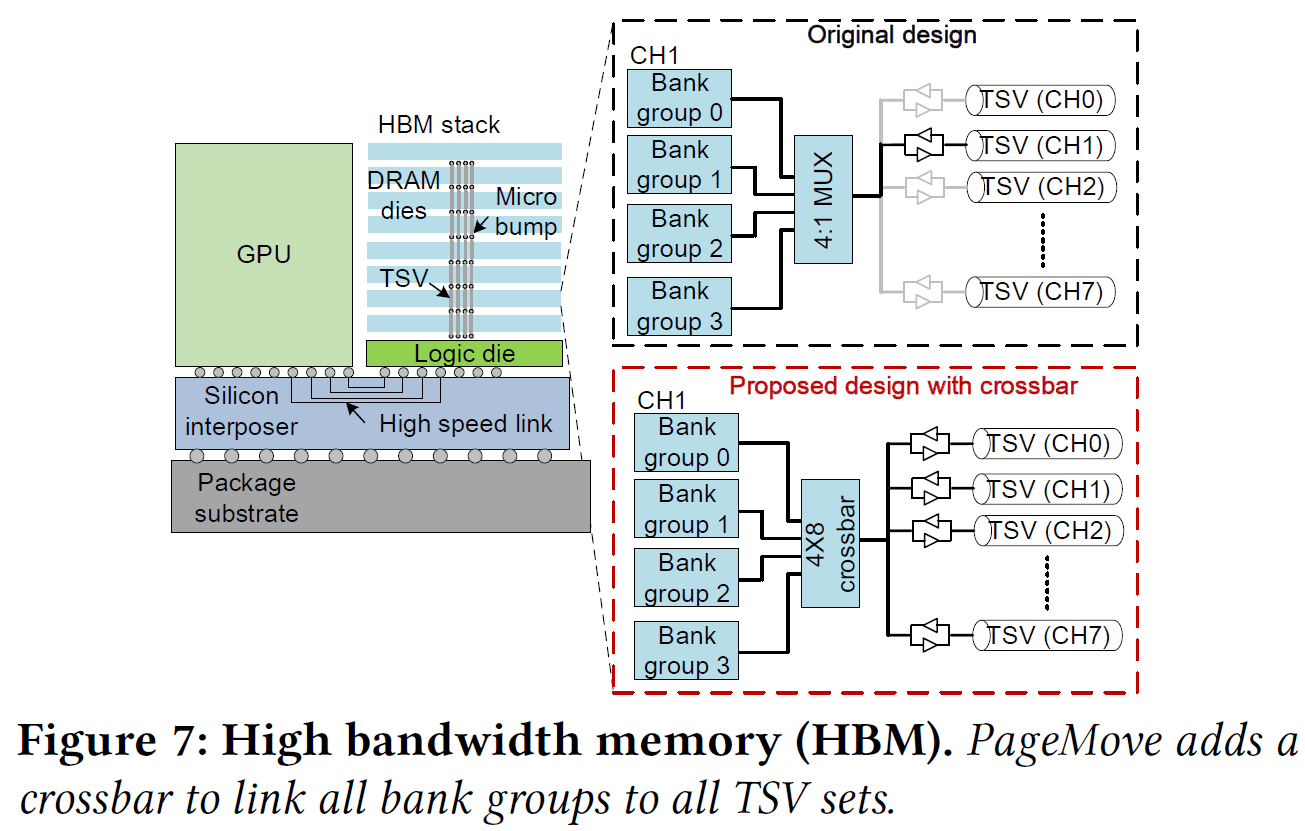
为实现这一目标,作者提出了两个关键技术:其一是需求感知的资源划分算法,不依赖复杂不精确的性能建模,而是基于当前运行应用对SM和内存的实际需求迭代调整分配。第二个挑战是高效的资源重分配机制:相比SM可通过上下文切换等手段动态划拨,内存通道的重新分配需要迁移大量数据,在GPU中尚属未解决难题。UGPU为此设计了PageMove机制(如下图7所示),在HBM堆栈内部实现快速页迁移,允许在不同内存堆叠层之间高效移动数据,以便安全地收回和重新分配内存通道,而对系统性能影响最小。这个机制是这篇工作能否实现目标的最重要内容,但涉及到对HBM的硬件改动,是否真的可行还有待观察。
REIS: A High-Performance and Energy-Efficient Retrieval System with In-Storage Processing
上面三个工作的背景都是大模型的计算需求,REIS则面向大模型应用的另一个重要技术,检索增强生成(RAG:Retrieval-Augmented Generation)。
RAG加速是本次会议很受关注的议题之一,至少有5篇文章从各个角度讨论相关问题。涉及体系结构从芯片设计、存储访问到系统调度等多方面的协同优化,充分体现了ISCA一贯重视的“软硬件协同”研究风格。
REIS主要针对RAG流程的瓶颈——海量数据检索阶段的I/O开销——提出了一种高性能、能效友好的存储内处理(in-storage processing)解决方案。
论文首先定量分析了RAG pipeline中检索阶段巨大的数据搬移开销,指出现有缓解I/O瓶颈的方案存在两大局限:其一,已有存储内近似最近邻搜索(ANNS)加速器主要关注向量相似搜索,加速“检索”子任务,却未优化后续的相关文档获取,导致整个检索流程仍受限于主机与存储间的数据传输;其二,这些方案往往通过专用硬件或增加存储冗余来提升ANNS性能,集成成本高、难以直接应用于RAG系统。为此,REIS 提出了首个专为RAG设计的存储内检索系统,实现三大关键创新:
首先,在存储设备内高效实现聚类式倒排文件(IVF)检索算法,利用SSD闪存内部多平面并行逻辑执行向量相似度计算,由SSD控制器直接筛选最相似的嵌入向量,以减少数据搬出存储的量。
其次,引入新的存储层数据布局,将向量嵌入和文档块分别存储并通过NAND闪存的带外(OOB)区域建立关联,这使SSD在找到相似向量后能直接定位并提取相应文档内容,显著加速文档检索。
再次,定制了存储内的ANNS计算引擎,巧妙地利用现代SSD已有的计算资源,结合二值量化降低计算复杂度,并采用SLC/TLC混合闪存架构(以高速可靠的SLC区域执行计算,容量更高的TLC区域存储文档),在无需新增硬件的情况下提升了计算性能和能量效率。

数据格式、低精度量化和处理
除了上述这几篇典型的系统级软硬件协同优化工作,我们再来看几篇涉及微架构的工作,主要讨论不同的数据格式,低精度量化和处理,这些是目前的AI计算加速低层架构设计的重要内容。
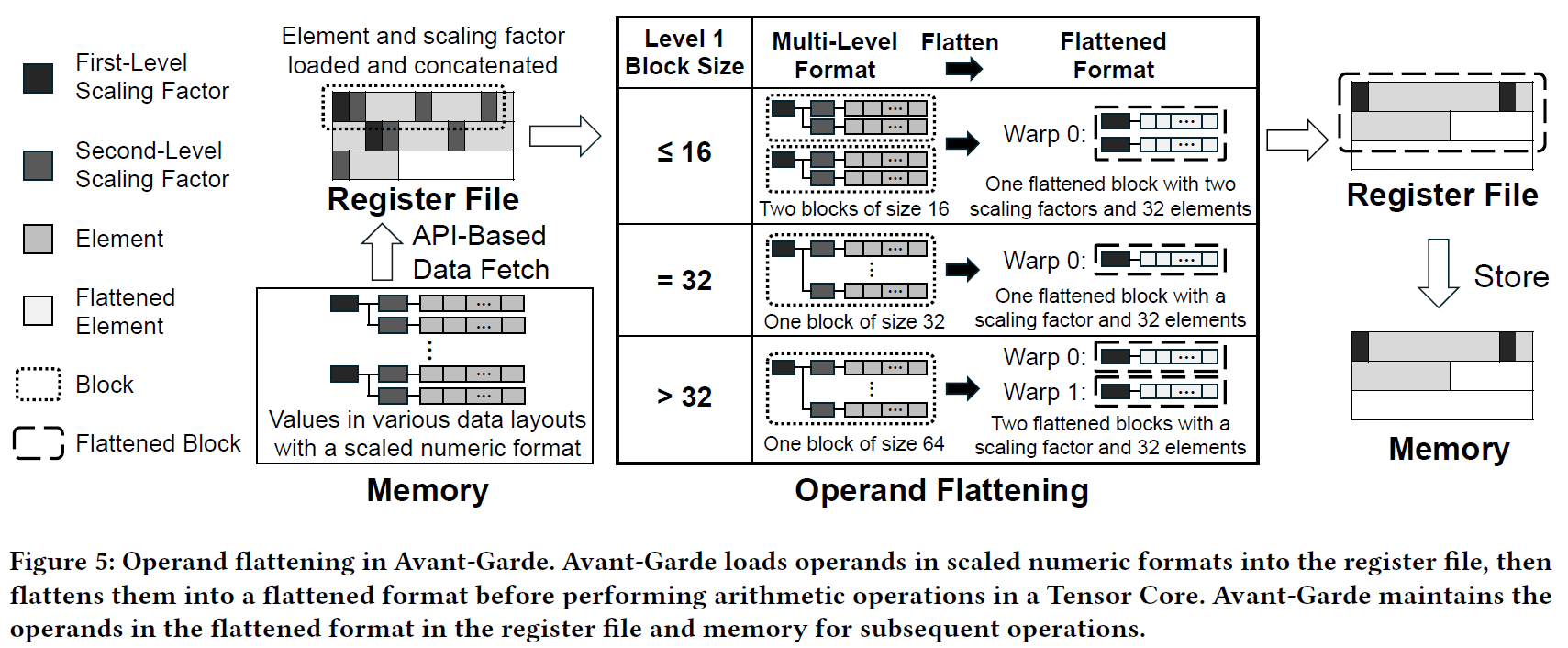
Avant-Garde: Empowering GPUs with Scaled Numeric Formats
这篇论文聚焦于GPU在深度神经网络计算中的算术密度瓶颈,针对现有GPU无法原生支持多级缩放数值格式(如FP8、MX格式)而依赖软件转换导致的性能开销问题。
该工作提出了一种创新的GPU微架构 Avant-Garde,通过在硬件中将多级缩放数值格式转换为统一的单级内部表示,实现对各种缩放数值格式的原生支持。其核心思想是在GPU中增设操作数变换器模块,将分块浮点等多级缩放表示“压平”(flattening)为单级表示供张量核心进行高效计算,并相应的重新设计了张量核心和优化的数据布局,以便在不改变内存存储格式的前提下高效管理不同块的缩放因子。这一架构消除了依赖软件处理缩放带来的指令和寄存器开销,大幅提升了GPU执行低精度深度学习工作负载时的算术运算密度。
该论文主要贡献在于:分析了GPU支持动态缩放格式的瓶颈,揭示缺乏硬件支持导致的低效;设计了首个原生支持多级缩放格式的GPU架构,整合Operand Transformer模块、新型张量核心和数据布局优化来提高计算效率。
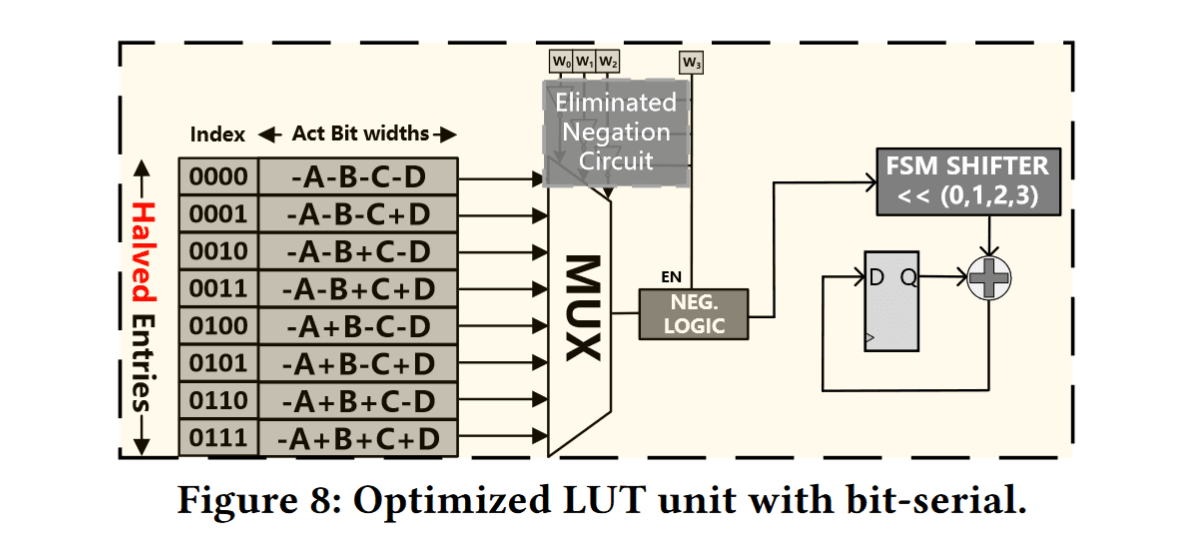
LUT Tensor Core: A Software-Hardware Co-Design for LUT-Based Low-Bit LLM Inference
这篇针对大语言模型低比特推理中的查找表(LUT)矩阵乘运算效率问题提出软硬件协同优化。传统LUT实现用于低精度矩阵乘法时往往因查找表预计算开销和重复计算等因素未能充分发挥预期性能优势。
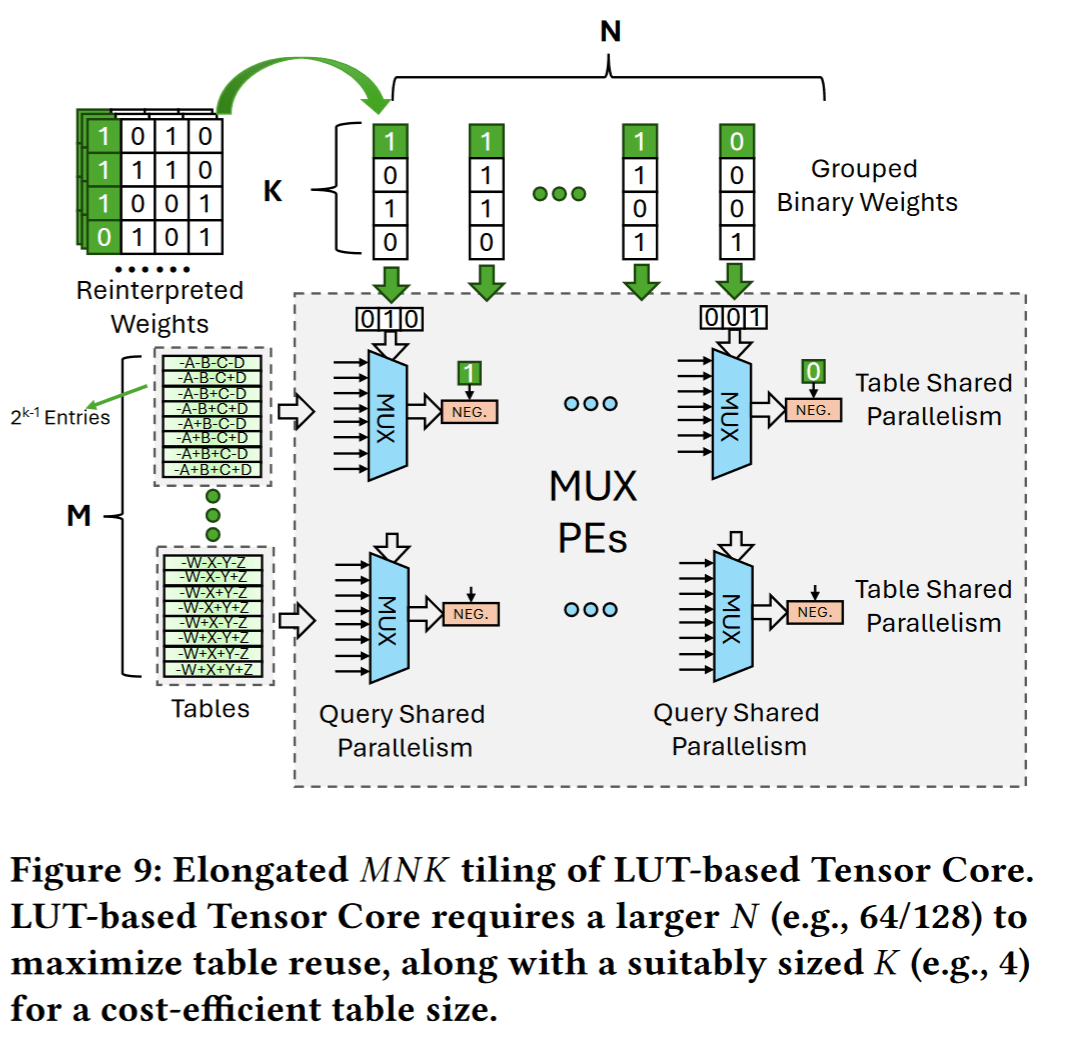
为此,该工作提出了LUT Tensor Core框架,从软件和硬件两个方面协同设计:一方面通过软件优化减少查找表预计算的冗余,将独立的查找表生成操作拆分重组,并利用权值重解释压缩查找表存储规模;另一方面定制了一种LUT驱动的张量核心硬件,采用加长的并行计算阵列划分来提高查找表重用率,并引入比特串行电路以支持多种权重和激活精度组合。
此外,还扩展了张量核心指令集(引入LMMA指令)并改进编译流程,以便将上述LUT优化高效融入现有GPU推理软件栈中。LUT Tensor Core 实现了相较纯软件LUT方案的数量级性能提升,且在相同面积功耗下计算密度比既有LUT加速器显著提高,能够兼容INT4/INT2/INT1等多种低精度配置,方便集成到现有硬件体系中以高效执行大模型推理。
Transitive Array: An Efficient GEMM Accelerator with Result Reuse
这篇论文提出了一种通过结果复用来加速矩阵乘运算(GEMM)的新范式。深度神经网络和LLM的计算往往被密集的矩阵乘法主导,即使采用低精度量化或稀疏技术仍然需要大量乘加操作。
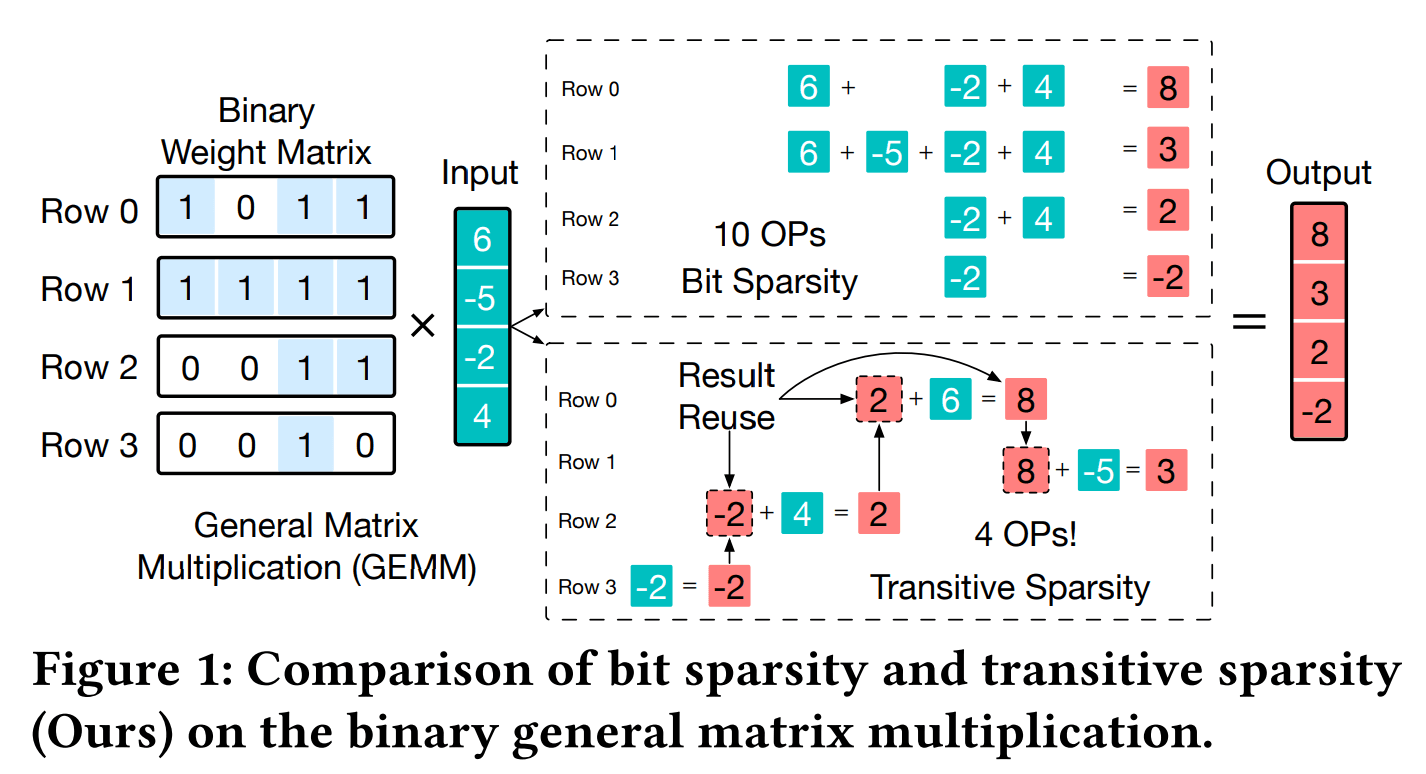
该研究发现了一种可利用的传递式稀疏性(transitive sparsity):不同矩阵计算中如果存在部分中间结果相同,就可以复用已有结果而避免重复计算。
具体而言,可将二值化后的矩阵行向量表示为0/1模式,通过构建有向无环图表示不同行向量之间的传递关系,找出其中可以共享的部分和最佳计算顺序,如下图所示。
为充分挖掘这种传递式稀疏性,作者设计了Transitive Array加速器,这是一种无乘法的矩阵乘专用架构。
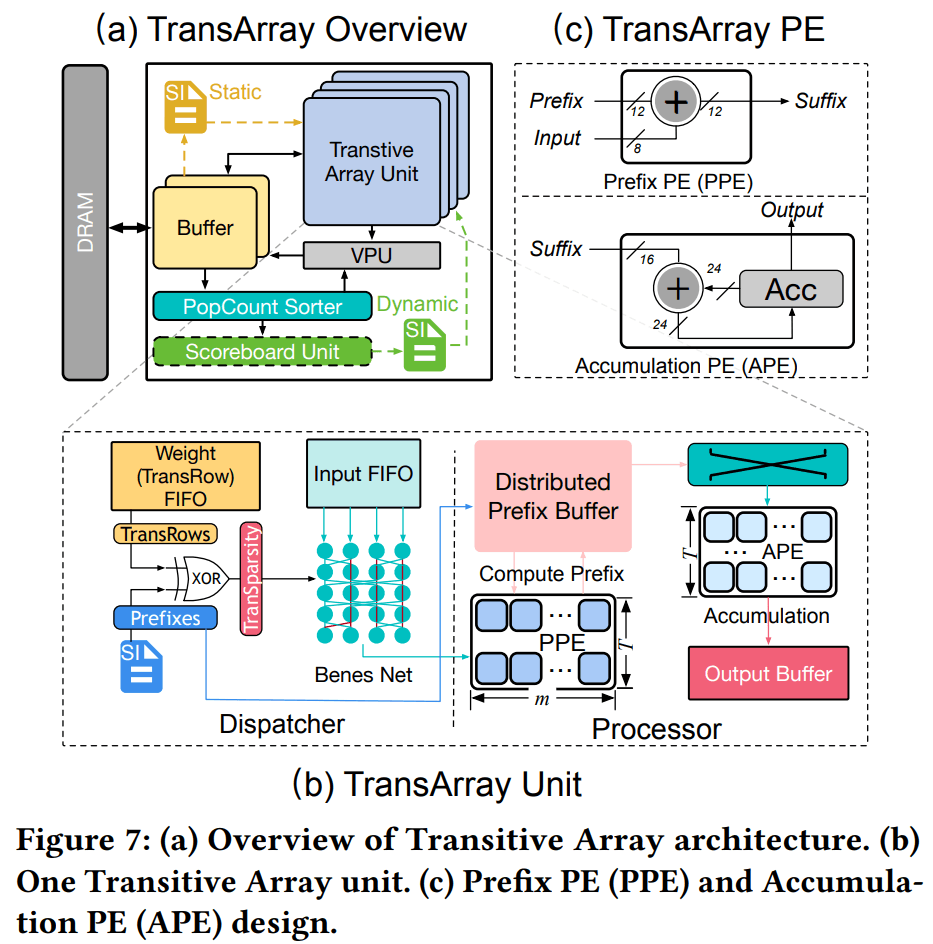
它通过预先分析量化后的权重矩阵,将矩阵乘转化为加法累加和数据搬移问题。Transitive Array利用Hasse图模型高效确定运算依赖顺序,将原本计算顺序优化问题的复杂度从指数级降低为线性级,并据此安排硬件执行顺序,以确保前序结果可用于后续计算。同时,针对传递复用导致的串行依赖和并行度受限问题,作者提出了将矩阵按行划分到多个并行通道的方法,并证明在适当划分下不同通道之间可消除依赖,实现并行执行。
此外,通过在调度前对不同稀疏度的计算任务进行负载均衡分配,Transitive Array能避免某些通道过载而其他通道闲置,从而保持高资源利用率。
综合这些设计,Transitive Array大幅减少了矩阵乘运算所需的总操作数。Transitive Array的主要贡献在于提出了传递式稀疏这一全新的降算方法,并从算法到架构全栈设计了相应机制以克服执行顺序和并行调度上的挑战,最终证明了通过结果复用可以高效提升矩阵乘推理的性能与能效。
性能分析和仿真
体系结构研究或者架构设计离不开性能分析和仿真,本次会议有一个Performance and Modeling的session,下面从中摘一篇论文和大家一起看看。
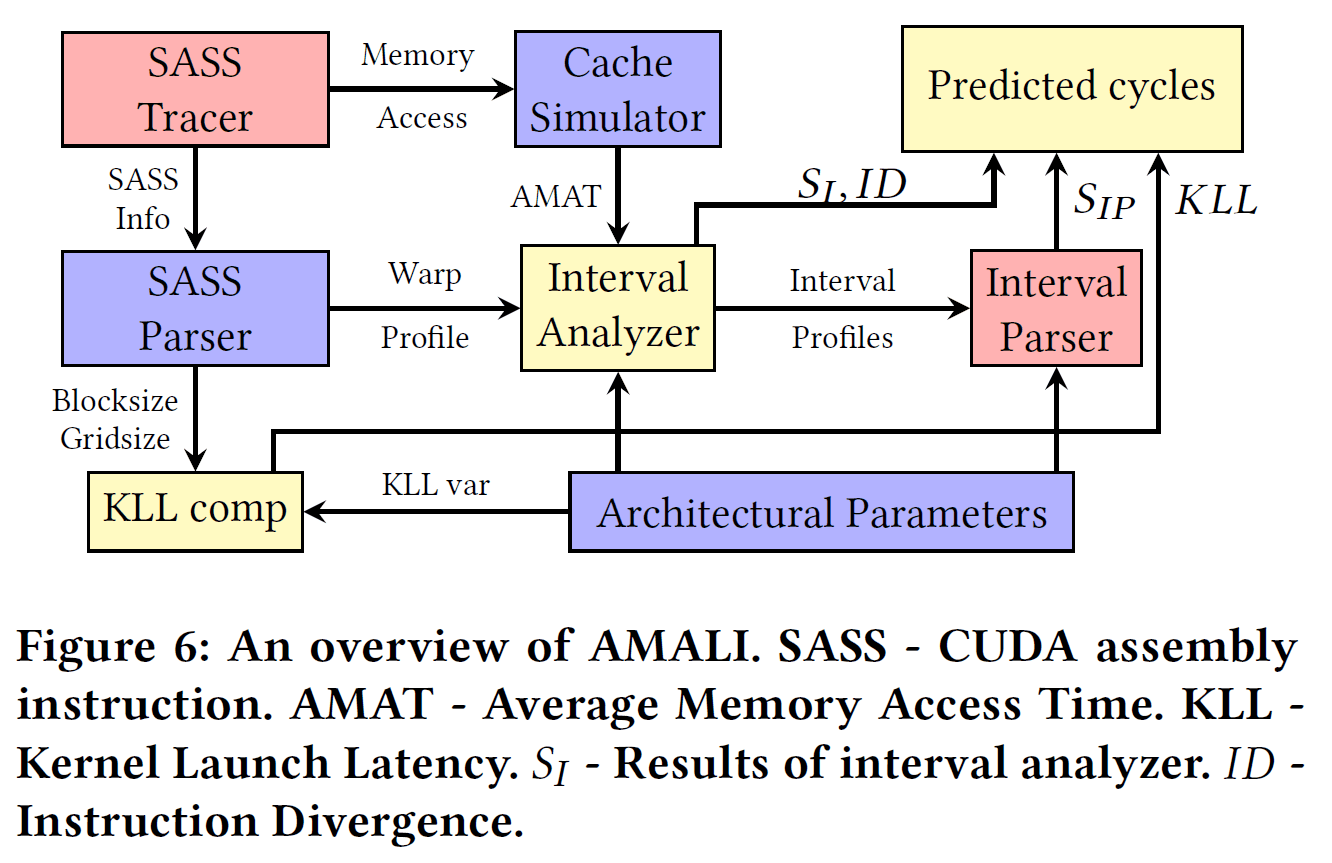
AMALI: An Analytical Model for Accurately Modeling LLM Inference on Modern GPUs
这篇论文仍然是针对LLM inference场景。由于这一场景的复杂性,简单的经验公式和简单峰值分析往往难以精确预估实际部署的性能。AMALI提出了一个针对现代GPU上LLM推理的精确分析模型。作者通过剖析LLM推理的pipeline,捕获Transformer各层计算与内存访问的重叠、GPU算力与带宽瓶颈等关键因素,并融合了显存KV缓存管理开销等在内的完整延迟模型。与以往只关注计算或内存单项瓶颈的模型不同,AMALI采用分段建模:对矩阵乘、注意力等算子分别建立性能方程,并考虑GPU上的并行执行特性(如流、多线程调度)将各部分综合成端到端延迟预测公式。这种方法可以根据LLM模型规模、GPU架构参数(CUDA核心数、带宽等)准确预测推理延迟和吞吐。对大模型部署性能的预测是整个系统优化的重要环节,相信后续还能看到更多这方面的工作。
一个有趣的探讨
最后,我们再来聊一聊一篇挺有意思的论文。
我们做架构设计一般都会在通用计算能力基础上针对应用场景进行优化,但头疼的问题是如果场景在芯片的设计过程和生命周期中发生变化怎么办?是尽量用通用的设计来应对,还是通过更专用的设计来更高效的处理已看到的workload?这篇论文就是在讨论这个问题。
Neoscope: How Resilient Is My SoC to Workload Churn?
这篇论文关注片上系统(SoC)在其生命周期中面临的工作负载变迁问题。硬件寿命越来越长,而所运行的软件工作负载不断演变,这可能导致最初设计时性能良好的SoC逐渐无法适应新的应用需求。为解决这一问题,该研究首先提出了定量描述工作负载随时间变化程度的概念框架,包括变化幅度(Magnitude)和冲击程度(Disruption)两个维度,将工作负载变迁(即“churn”)划分为Minimal、Perturbing、Escalating和Volatile四种类型,如下图所示。
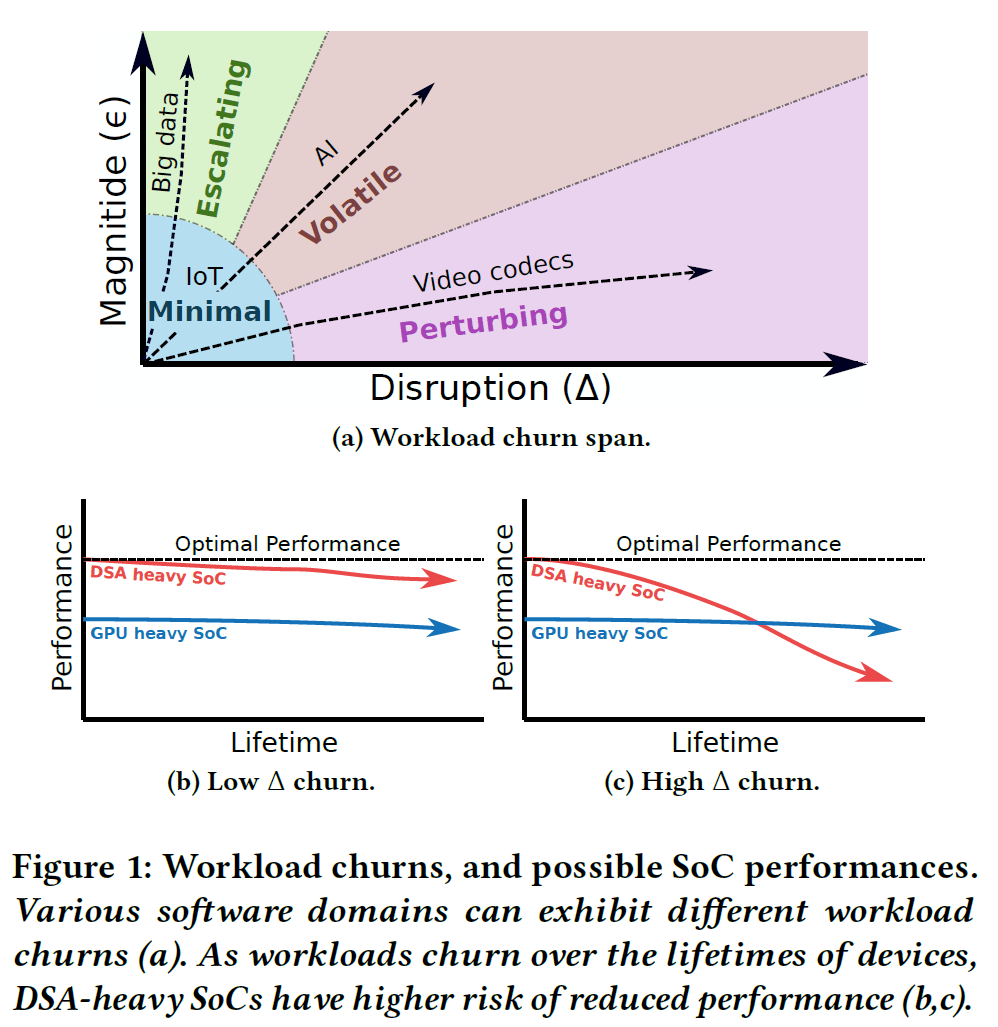
基于这一表征方法,作者开发了Neoscope工具——首个面向工作负载变迁鲁棒性的多目标SoC设计空间探索框架。Neoscope 将SoC早期设计建模为一个多目标优化问题,运用整数线性规划和job-shop调度等技术手段,在无需穷举搜索的情况下一次性求解接近全局最优的SoC配置方案,不仅考虑性能,还支持面积、能耗、成本和碳排放等多重优化目标,如下图所示。
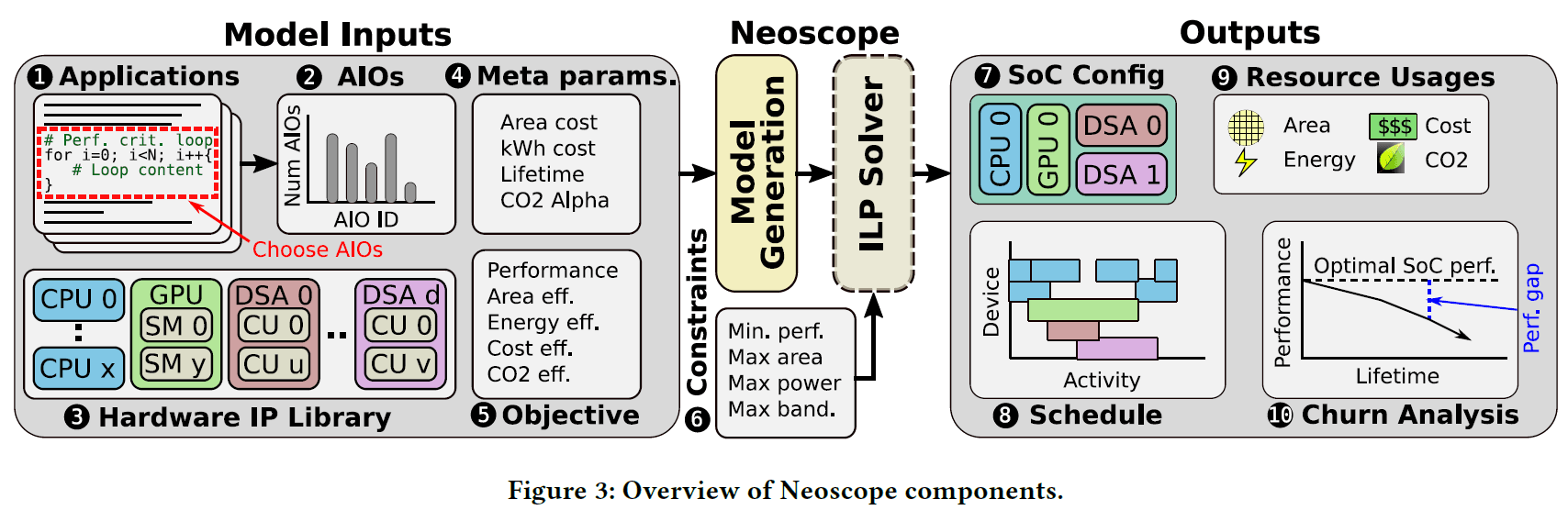
Neoscope可能是我们看到的第一个用理论方法和优化工具探讨“更专用还是更通用?”这个问题的工作,虽然考虑到架构设计的复杂性,这项工作有效性还有待观察,但至少是个很有意思的探索。
总结与展望
ISCA 2025大会内容丰富多彩,全面反映了当前体系结构研究的繁荣与活力。无论是由AI大模型驱动的新型计算需求,还是量子计算等新兴计算范式的兴起,都为体系结构研究带来了大量新的课题和机遇。本文中列举的内容只是冰山一角。其他诸多热点也在大会上得到深入探讨:如多篇论文关注量子体系结构的设计与优化(包括容错量子计算、量子存储管理、量子互联技术等方向),试图在量子门电路和量子纠错等关键问题上取得突破;而ISCA的传统研究内容如微结构设计、访存和Cache、存内计算、安全计算等等也并未停滞,总有新的创新工作涌现。如果再加上周末期间举办的众多workshop和tutorial,覆盖从硬件加速器到体系结构教育等主题,会议日程可谓目不暇接、亮点纷呈。
总的来看,当前体系结构研究正处于一个机遇与挑战并存、快速发展的阶段。层出不穷的新兴需求和新的芯片技术为该领域带来了大量具有高价值的研究问题,这些方向尚未走向稳定成熟,而是持续开启新的探索空间。未来几年,体系结构研究仍将围绕AI大模型、量子计算等热点展开,同时继续深入核心基础课题,不断推动计算机系统设计的创新。对于科研人员而言,ISCA会议提供了重要的参考和启发,也预示着该领域未来的研究趋势,值得持续关注。
参考文献
1. C. Zhao, C. Deng, C. Ruan, D. Dai, H. Gao, J. Li, L. Zhang, P. Huang, S. Zhou, S. Ma, W. Liang, Y. He, Y. Wang, Y. Liu, and Y. X. Wei. 2025. Insights into DeepSeekV3: Scaling Challenges and Reflections on Hardware for AI Architectures. In Proceedings of the 52nd International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 14 pages. https://doi.org/10.1145/3695053.3731412
2. Zheng Xu, Dehao Kong, Jiaxin Liu, Jinxi Li, Jingxiang Hou, Xu Dai, Chao Li, Shaojun Wei, Yang Hu, and Shouyi Yin. 2025. WSC-LLM: Efficient LLM Service and Architecture Co-exploration for Wafer-Scale Chips. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 17 pages. https://doi.org/10.1145/3695053.3731101
3. Seungjae Moon, Junseo Cha, Hyunjun Park, and Joo-Young Kim. 2025. Hybe: GPU-NPU Hybrid System for Efficient LLM Inference with Million-Token Context Window. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 13 pages. https://doi.org/10.1145/3695053.3731051
4. Xia Zhao, Guangda Zhang, Lu Wang, and Huadong Dai. 2025. UGPU: Dynamically Constructing Unbalanced GPUs for Enhanced Resource Efficiency. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 14 pages. https://doi.org/10.1145/3695053.3731103
5. Kangqi Chen, Rakesh Nadig, Andreas Kosmas Kakolyris, Manos Frouzakis, Nika Mansouri Ghiasi, Yu Liang, Haiyu Mao, Jisung Park, Mohammad Sadrosadati, and Onur Mutlu. 2025. REIS: A High-Performance and Energy-Efficient Retrieval System with In-Storage Processing. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 22 pages. https://doi.org/10.1145/3695053.3731116
6. Minseong Gil, Dongho Ha, Simla Burcu Harma, Myung Kuk Yoon, Babak Falsafi, Won Woo Ro, and Yunho Oh. 2025. Avant-Garde: Empowering GPUs with Scaled Numeric Formats. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 13 pages. https://doi.org/10.1145/3695053.3731100
7. Zhiwen Mo, Lei Wang, Jianyu Wei, Zhichen Zeng, Shijie Cao, Lingxiao Ma, Naifeng Jing, Ting Cao, Jilong Xue, Fan Yang, and Mao Yang. 2025. LUT Tensor Core: A Software-Hardware Co-Design for LUT-Based Low-Bit LLM Inference. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 15 pages. https://doi.org/10.1145/3695053.3731057
8. Cong Guo, Chiyue Wei, Jiaming Tang, Bowen Duan, Song Han, Hai Li, and Yiran Chen. 2025. Transitive Array: An Efficient GEMM Accelerator with Result Reuse. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 15 pages. https://doi.org/10.1145/3695053.3731043
9. Cao, S., Wu, J., Chen, J., An, H., & Yu, Z. (2025). AMALI: An Analytical Model for Accurately Modeling LLM Inference on Modern GPUs. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA '25). ACM. https://doi.org/10.1145/3695053.3731064
10. Joseph Rogers, Lieven Eeckhout, Taha Soliman, and Magnus Jahre. 2025. Neoscope: How Resilient Is My SoC to Workload Churn?. In Proceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25), June 21–25, 2025, Tokyo, Japan. ACM, New York, NY, USA, 15 pages. https://doi.org/10.1145/3695053.3731014