
图神经网络加速器深度调研(上)
发布时间:2021-04-17 11:02
摘要
近年来,图神经网络(Graph Neural Networks,GNNs)因为具有对图结构数据进行建模和学习的能力,而引起了机器学习领域研究者的广泛关注。在化学、网络、社交媒体、知识表示等领域,由于数据本身具有复杂的联系,通常采用图(Graph)作为数据结构来表示这种关系。随着各种GNN算法变体的发展,给这类可以建模为图结构数据处理任务的领域,带来了突破性结果。但是,在目前的研究阶段,GNN的高效计算仍然是一个非常开放的问题。最主要的原因来自于GNN的计算图依赖于同时存在的输入复杂结构的图数据,计算密集的操作和稀疏访存的操作等复杂行为,使得传统的通用计算架构、并行计算架构,或者是定制的图处理架构在面对GNN任务时都遇到了一定的困难。为此,出现了一系列软件框架工作或硬件加速器设计工作,分别希望更加充分地利用现有并行计算器件的能力进行GNN的计算,或设计适应GNN计算任务特点的专用硬件达到更高的速度或能效。
不过,目前的架构设计工作还是探索性的,针对GNN计算任务进行特定架构设计的目标、关键问题定义、通用技术等还不清晰,不同架构的比较也没有明确统一的标准。此外,从计算任务上来说,各种GNN算法变体之间的计算图差异较大,且新算法迭代很快,相同的算法用于不同的任务,计算负载特征也会有较大不同。所以,现有的加速器研究还不能满足要求。针对这样的情况,我们通过对GNN算法的调研,给出了GNN算法的统一建模框架,便于分析GNN计算的特点,指导加速器设计工作,也为下一步从GNN计算任务到构建特定硬件架构并部署的完整流程研究提供了桥梁;通过对现有GNN加速器的调研,我们指出了现有GNN加速器设计的优劣,总结了关建问题、一般设计方法,提出未来的发展趋势,指导加速器设计工作。
本系列文章笔者钟凯为清华大学清华大学电子工程系博士生;戴国浩为清华大学电子工程系助理研究员、博士后。该文工作得到清华大学和壁仞科技研究院联合研究项目的支持。
1、简介
目前,以神经网络(NN)为代表的机器学习(ML)算法在计算机视觉1、自然语言处理2、智能体决策3等各个领域都得到了广泛应用,并已成为工业生产的下一代动能。在过去的十几年中,由于计算机硬件技术的进步和配套算法研究的发展,计算量和模型参数量较大的深度神将网络(DNNs)可以被有效训练,并有能力在数据驱动下自动化学习到复杂的特征识别方法,解决复杂的问题,并在各个领域取得了超过传统方法的成果。然而,并非所有的神经网络架构都能用于所有问题4,对于不同的任务,需要针对性设计对应的神经网络算法,而这些算法的实现从原理、实际架构到训练方式都有较大不同。最简单的多层全连接网络是神经网络的基本模型,从理论上说,DNN的数据、宽度、层间连接关系决定了网络的特性,例如CNN利用卷积的思想,通过局部连接和权重共享提取空间排列的神经元之间的模式信息5,而RNN则对在时间上排列的神经元序列进行模式特征提取6。
除了上述两种典型的神经网络,最近人们对图结构数据建模任务产生了较大兴趣,因为很多复杂系统中的数据都有图结构的特点,例如:网络平台上,人与物的信息和交互可以建模为图7;通信网络中,决定其性能关键的节点路由器资源和连线组成的拓扑图8,还有化学中研究的分子结构构成的图9,佳通流研究相关的结构图10等。不同于CNN处理的空间排布数据和RNN处理的时间排布数据,图数据具有连接不规则、维度高等特性。图神经网络(GNNs)就是一种尝试用神经网络的思想,建模图结构数据的算法,。从本质上讲,不同于CNN和RNN处理的有规则的空间连接或时间连接的结构,GNN的网络结构是由所处理的图结构定义形成,其处理过程是通过相似的跨顶点的信息传递形成网络,迭代训练有参数的传递函数,从而提取节点间应有的依赖关系,最终预测节点、连接或整个图的特性。
近几年出现了GNN研究的热潮,主要思想也在不断发展变化。GNNs的概念最初在[11]中概述,并在[12]和[13]中进一步阐述。由于卷积神经网络(Conlolutional Neural Network,CNN)在计算机视觉领域的成功应用,出现了大量重新定义图数据卷积概念的方法,主要分为两大主流:基于谱的方法和基于空间的方法。Bruna等人14提出了基于谱的图卷积的第一个重要研究成果,从那时起,基于谱的图卷积神经网络(Graph Convolutional Network,GCN)得到了越来越多的改进、扩展和近似151617。基于空间的图卷积的研究起步比基于谱的更早。在2009年,Micheli18首先通过架构上组合非递归层来解决图的相互依赖性,但直到最近,才出现了更多基于空间的GCN192021。
但是目前GNN的高效计算仍然是一个开放问题,这是因为GNN相对于与已经被研究了多年的CNN和RNN拥有更独特的计算模式,包括需要(i)同时支持密集和稀疏运算,(ii)适应各种GNN算法变体和不同的图数据结构,以及(iii)扩展到非常大的图,以实现实际应用的部署。
为此,出现了一系列软件框架工作,使得我们能够更加充分地利用现有并行计算器件的能力进行GNN的计算。比如PyG22和DGL23是两个广泛使用的开源库,他们都定义了基于消息传递模型的编程接口,但在GPU上实际执行时分别采用分散聚集内核和稀疏矩阵乘法内核来处理图的稀疏结构,这也是两种最具代表性的处理方式。除了学术上应用较多的上述两个框架,很多业界公司开发了在实际场景中应用的框架,比如Facebook发布的Pytorch BigGraph24,Microsoft开发的NeuGraph25,Alibaba开发的AliGraph26,Amazon开发的FeatGraph27等。这些工作深入研究了图分块的方式、内存调度方式、分布式处理方法等问题来更好地支持任意大的图在实际系统中的部署。
除了在通用CPU和GPU计算平台上运行的软件框架,还有一些专用硬件加速器设计出现,目标是设计适应GNN计算任务特点的专用硬件模块以达到更高的速度或能效。HyGCN28和EnGN29是两个出现较早的代表工作,分别采用了双模块式架构和统一处理阵列架构。同样采用统一处理阵列架构的AWB-GCN30主要聚焦于GCN算法中的负载均衡优化。双模块式架构得到了较多后续改进工作的采用,比如相比于HyGCN更灵活地支持了更多GNN的GRIP31、利用片上网络(Network on Chip,NoC)实现可扩展性同时处理稀疏访问的GNNA32、采用离线数据预处理算法进行软硬件协同优化的33以及用于加速GNN训练的GraphACT34。
不过,目前的架构设计工作还是探索性的,针对GNN计算任务进行特定架构设计的目标和关键问题定义还不清晰,不同架构的比较也没有明确统一的标准。此外,从计算任务上来说,各种GNN算法变体之间的计算图差异较大,且新算法迭代很快,相同的图神经网络算法用于不同的图数据和任务,计算负载特征也会有较大不同,加速器架构设计工作需要更多地考虑到对于各种算法的通用性和执行不同特征的负载的效率。针对这些情况,本文通过建模并分析GNN算法的计算特征,对比现有的GNN加速器工作给出GNN加速器设计的要点和一般方法。
本文的其余部分安排如下:第2节进行计算任务分析,提出GNN算法的统一模型,介绍常见的GNN算法;第3节进行加速器工作调研,提出了加速器设计评价指标并介绍了现有GNN加速器工作;第4节分析了GNN加速器设计的关键技术;第5节给出了加速器设计的启发和发展前景展望;第6节进行总结。
2、计算任务分析
2.1 GNN基础表示符号
在本节我们介绍GNN相关的基础符号并总结为下表1。图是一种由节点,和连接节点的边组成的结构。在这里,我们将图定义为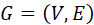 ,其中V表示顶点集,E表示边集,节点和边的数量分别
,其中V表示顶点集,E表示边集,节点和边的数量分别 和
和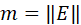 。
。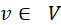 是V中的一个节点,
是V中的一个节点,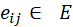 是E中的一条边,对于每一条边
是E中的一条边,对于每一条边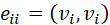 表示其连接的两个节点是
表示其连接的两个节点是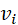 和
和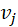 。对于有向图,和的顺序表示有一条从指向的边。对于一些图数据,允许从一个节点连接到同一个节点的边,称为自环,即。对于每一个节点
。对于有向图,和的顺序表示有一条从指向的边。对于一些图数据,允许从一个节点连接到同一个节点的边,称为自环,即。对于每一个节点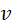 ,可以用
,可以用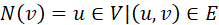 表示其被一条边所连接到的邻居节点组成的集合,在有向图中,可以分别用
表示其被一条边所连接到的邻居节点组成的集合,在有向图中,可以分别用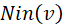 和
和 区分入边连接到的节点集合和出边连接到的节点结合,在我们后续叙述中,由于GNN的特性,我们用
区分入边连接到的节点集合和出边连接到的节点结合,在我们后续叙述中,由于GNN的特性,我们用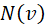 统一表示节点的邻居节点集合,对于有向图只考虑入边组成的集合。邻接矩阵
统一表示节点的邻居节点集合,对于有向图只考虑入边组成的集合。邻接矩阵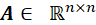 是一个稀疏矩阵,其中的每个元素
是一个稀疏矩阵,其中的每个元素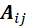 在
在 时为1,反之为0。
时为1,反之为0。
一般地,顶点和边都可以用一个或多个属性进行属性化。在对于GNN的讨论中,每个顶点有一个节点特征表示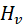 ,每个边
,每个边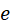 有一个边缘特征表示
有一个边缘特征表示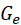 。顶点或边的特征表示通常是一个向量,由多个标量属性构成,也可能只有一个标量,设每个节点特征是一个
。顶点或边的特征表示通常是一个向量,由多个标量属性构成,也可能只有一个标量,设每个节点特征是一个 维向量,则整个网络的特征向量构成矩阵
维向量,则整个网络的特征向量构成矩阵 。类似地,整个网络的边特征可以表示为一个矩阵,
。类似地,整个网络的边特征可以表示为一个矩阵, 是一个边特征向量的维度。现实世界产生的图数据,例如社交网络,通常具有一些特征35:首先是稀疏性,即平均顶点度数很小,图的稀疏性会导致数据随机访问,局部性较差问题。其次幂律分布,即少数顶点度数很大,关联了大多数边,这可能导致严重的工作负载不平衡问题,在更新高度顶点时会出现大量的访问冲突。最后是小世界结构,即图中的任意两个顶点可以用少量的跳数连接起来,小世界特性将使图的有效划分变得困难。
是一个边特征向量的维度。现实世界产生的图数据,例如社交网络,通常具有一些特征35:首先是稀疏性,即平均顶点度数很小,图的稀疏性会导致数据随机访问,局部性较差问题。其次幂律分布,即少数顶点度数很大,关联了大多数边,这可能导致严重的工作负载不平衡问题,在更新高度顶点时会出现大量的访问冲突。最后是小世界结构,即图中的任意两个顶点可以用少量的跳数连接起来,小世界特性将使图的有效划分变得困难。
对于GNN算法来说,除了图本身的数据结构,还存在一系列的网络表示。GNN通常被抽象成多层,假设总层数为L。每层的计算过程总结就是,根据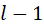 层的节点和边特征,以及邻接矩阵,计算
层的节点和边特征,以及邻接矩阵,计算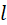 层的特征,最终得到第L层特征即输出特征。计算中对节点的更新和边的更新分别用到两种权重,记为
层的特征,最终得到第L层特征即输出特征。计算中对节点的更新和边的更新分别用到两种权重,记为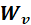 和
和 ,在具体网络中和的形状、数量与网络定义有关。
,在具体网络中和的形状、数量与网络定义有关。
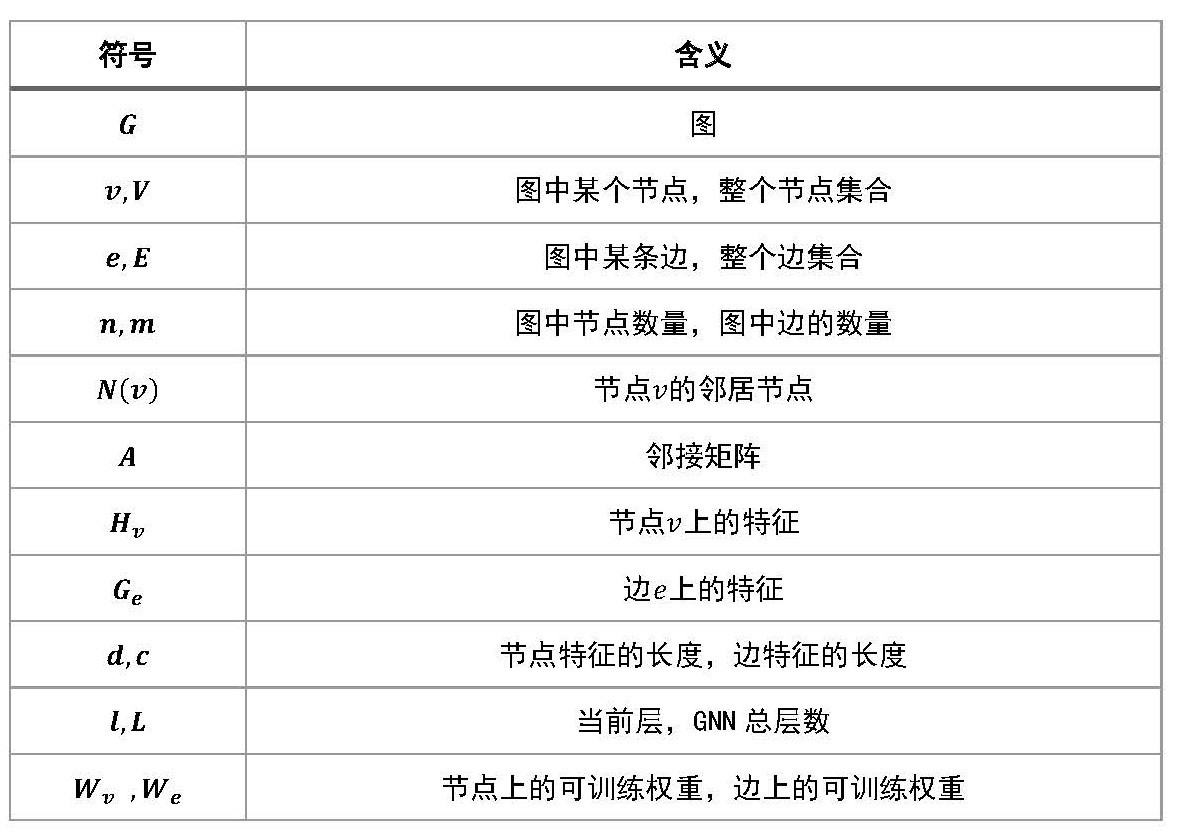
表1 GNN相关的基础符号
2.2 GNN前向计算模型
通过对一系列的GNN算法进行总结,我们将目前通用的GNN前向计算抽象成一个多阶段的计算模式,包括五个阶段,分别是:数据预处理、边消息提取、节点消息聚合、节点特征变换、后处理。这五个阶段中,边消息提取,节点消息聚合,节点特征变换三个阶段是GNN模型本身的操作,也是加速器研究的重点。数据预处理与GNN模型可以是解耦的,即不同的预处理方法可能匹配各种具体的GNN模型,并非必须一一对应,但这部分操作作为系统的一部分与性能息息相关,而且会影响到加速器的输入数据格式和实际运行效率,也是评估加速器设计时不得不考虑的因素。后处理则大部分是与GNN模型解耦的,少部分在GNN模型中间进行池化操作的,也被我们归为后处理,这一小部分是与GNN模型耦合的,在评估这部分操作时,主要涉及到加速器的通用性。
(1)数据预处理
我们将数据预处理(Pre-Processing)定义为在进行GNN网络模型中的计算之前,对图数据的数据结构进行处理,或对算法执行流程进行规划的阶段,如图1所示。在很多软件框架工作和加速器设计中,都提出了图数据的分块、节点顺序调整等数据预处理方法,这些预处理方法能够让GNN真正计算所依赖的图结构具有一定的聚集性,从而在执行中增加数据局部性,减少随机访存或缓存缺失,对于较大的图,则能够更好地减少节点间通信量。此外,对于不需要计算所有节点输出值的GNN前向计算任务,其每一层都可能不必计算整个网络,只需要从需要的输出反推,得到与输出节点有关联的子图,生成所谓的节点流(Nodeflow),再依据Nodeflow(而不是整个Graph)进行GNN计算。这种对于计算任务的裁剪和规划,我们也将其算作预处理阶段,在这个过程中,也可以基于得到的Nodeflow做图数据的预处理。
预处理阶段的操作需要注意的是代价问题,对于每个计算任务Nodeflow控制流的生成以及对应的数据预处理,如果代价过大,甚至会占据一次前向计算代价的主要部分,即使能够在真正进行模型计算时达到比较好的任务缩减和易于调度的效果,在总体延时和计算能耗等指标上可能也没有优势。对于全图进行的数据预处理更是如此,所以必须要保证花费较多的开销进行预处理后,模型的计算任务会执行多次,且都能从预处理中受益,这样才能掩盖提前离线预处理的开销。
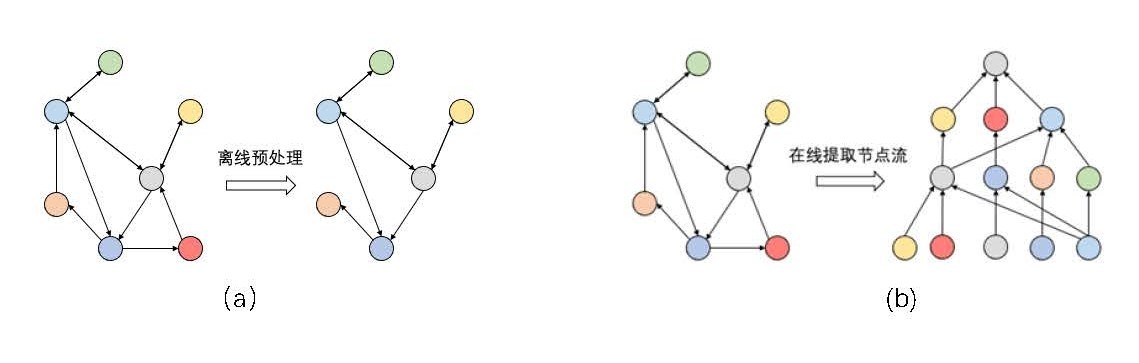
图1 两种典型的预处理阶段操作示意图
(2)边消息提取
我们将边消息提取(Edge Message Extraction,EME)定义为在图的一条边上进行,以一条边的特征、其连接的两个节点特征、全局信息、网络权重为输入,计算得到一条边上的新特征的操作,如图2所示。新特征称之为消息,可能作为本层的新边特征直接进行边特征更新,也可能用于节点消息聚合阶段。在实际网络中,生成的消息可能是向量,也可能是向量和标量的组合;生成的过程也大不相同,可能是直接传递而不作任何修改,或者简单的向量数乘,也可能是复杂的矩阵计算和向量点积等。如果该层GNN的计算是在全图上进行,那么边消息提取操作次数为边的数量m,生成的消息数量也是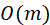 量级的,每条边生成有
量级的,每条边生成有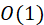 的消息。
的消息。
在我们的分析框架中,我们认为边消息提取不是主动执行的一个独立的阶段,每个边消息的提取都从属于目标节点的消息聚合操作,由消息聚合阶段发起和依赖;且从图结构和GNN的定义上看,边上提取的消息只能为其自身或目标节点所用,不具有全图上甚至仅仅是局部的数据重用能力,真正有重用特性的是提取前的节点特征,所以可以认为这个阶段是本地操作,不用考虑稀疏访存特性。
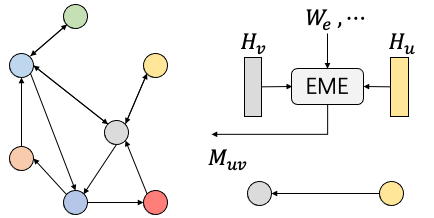
图2 边信息提取操作模型
(3)节点消息聚合
我们将节点消息聚合(Vertex Message Aggregation,VMA)定义为在图的一个节点上进行的,以不定量的入边上的消息、本节点的特征、全局信息、网络权重为输入,计算该节点上的聚合结果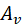 的操作,如图3所示。VMA是一个多输入一输出的操作,所以称之为聚合,从整个网络来看,输入是
的操作,如图3所示。VMA是一个多输入一输出的操作,所以称之为聚合,从整个网络来看,输入是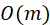 的,输出是
的,输出是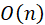 的。其中EME阶段的结果
的。其中EME阶段的结果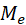 是VMA阶段的输入,但输入包含多少条入边消息是不定量的,取决于聚合算法和网络结构,如果聚合算法是聚合所有入边,则由于图的特性,不同的节点进行消息聚合时显然输入数目是不一样的,这也是计算单元负载不均衡的原因。如果聚合算法是在邻居节点中采样固定数量的进行聚合,在预处理阶段已经对图结构进行处理,则不同节点聚合时输入消息数量可以是一样的,这种算法有助于消除负载不均衡问题,但受限于硬件资源仍然无法完全解决。但无论如何,聚合消息的来源取决于图的连接关系,是不连续的,虽然在将边消息提取看做节点消息聚合的子操作时,对于不连续数据真正的读取发生在边消息提取前,但本质原因是节点聚合操作的特性。所以我们认为,节点消息聚合是GNN区别于CNN的特征操作。
是VMA阶段的输入,但输入包含多少条入边消息是不定量的,取决于聚合算法和网络结构,如果聚合算法是聚合所有入边,则由于图的特性,不同的节点进行消息聚合时显然输入数目是不一样的,这也是计算单元负载不均衡的原因。如果聚合算法是在邻居节点中采样固定数量的进行聚合,在预处理阶段已经对图结构进行处理,则不同节点聚合时输入消息数量可以是一样的,这种算法有助于消除负载不均衡问题,但受限于硬件资源仍然无法完全解决。但无论如何,聚合消息的来源取决于图的连接关系,是不连续的,虽然在将边消息提取看做节点消息聚合的子操作时,对于不连续数据真正的读取发生在边消息提取前,但本质原因是节点聚合操作的特性。所以我们认为,节点消息聚合是GNN区别于CNN的特征操作。
图3 节点消息聚合操作模型
(4)节点特征变换
我们将节点特征变换(Vertex Feature Transformation,VFT)定义为在一个节点上进行操作,如图4所示,其过程是以本节点特征、本节点聚合消息结果、全局信息、网络权重为输入,计算本节点的新特征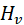 ,并作为本层GNN的输出进行更新。其中,VMA阶段的结果
,并作为本层GNN的输出进行更新。其中,VMA阶段的结果也是VFT阶段的输入,从全图来看,输入和输出的数量都是
 的。
的。
节点特征变换的特点是只在网络的每个节点内单独进行,但权重一般会在不同节点间共享。被变换的特征可能是本节点特征与聚合的消息特征,也可能只有消息特征。常见的变换方式有一层或多层的全连接网络(Fully Connected Network,FCN)、循环神经网络(Recurrent Neural Network,RNN)等。
图4 节点特征变换操作模型
(5)后处理
后处理(Post Processing)是指在GNN完成边和节点的计算后,对整个网络或一个子网络的输出特征进行进一步处理的操作。常见的操作一般都是池化(Pooling),可以缩减数据规模。而池化操作又分为两类:一类是全局池化,得到整个图的特征(前面的GNN计算都是得到节点和边的特征),可以采用无参数的池化方式,也可以采取有参数的特征组合方式;另一类是局部池化,将图中邻近的节点特征进行缩减,图的结构中也将多个节点变为一个,减少图的规模同时得到精炼的特征,进行后续分析。
后处理一般是网络应用于实际任务的必要步骤,一般在图神经网络其他计算结束后,有时要在网络的多层间进行,如果开销可观,也需要计算系统较好的支持。全图一致操作的后处理因为不涉及网络结构的不规则计算,一般比较容易实现,具体操作一般也与GNN中的节点迭代计算类似;子图池化的后处理使得图结构也发生变化,是比较难支持的操作。
2.3 典型GNN模型
根据上述计算模式模型,我们可以对当前的几个典型GNN算法进行分析,每种算法可以有一种或多种方式对应到这个多阶段计算模型。如前所述,预处理和后处理阶段大多数情况下与GNN模型本身解耦,所以我们主要介绍四种GNN的模型计算部分阶段划分。
(1)GCN
GCN36是最早被提出的图卷积神经网络,其边信息提取方式较为简单,为直接复制源节点特征作为待聚合消息;其节点特征聚合操作为将所有待聚合消息相加;节点特征更新为通过两个矩阵向量乘法结果的和,并组合本地特征和聚合特征。综上,其一层的阶段划分模型如表2所示。表2 GCN一层阶段划分模型列表

表2 GCN一层阶段划分模型列表
(2)GraphSage
GraphSage37这篇研究工作的很多贡献体现在预处理阶段的采样算法和Nodeflow构建上,但其网络模型结构设计也很有特点。边消息提取方式是一层全连接网络;节点消息聚合可选用多种聚合函数,包括最大值,加法等;节点特征变换则与GCN相似,将两个矩阵向量乘法结果相加。综上,其一层的阶段划分模型如表3所示。

表3 GraphSage一层阶段划分模型列表
(3)GAT
GAT38利用注意力机制(attention)进行设计,边消息提取阶段首先对源节点进行K个矩阵向量乘法,得到称之为K个attention head的特征向量,每个记作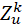 ,同时需要计算目标节点同样的K个head的特征
,同时需要计算目标节点同样的K个head的特征 ,然后这K对特征分别拼接起来,与K个可学习的注意力权重向量
,然后这K对特征分别拼接起来,与K个可学习的注意力权重向量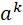 进行向量点积并通过Leaky ReLU函数进行非线性激活,计算得到注意力系数
进行向量点积并通过Leaky ReLU函数进行非线性激活,计算得到注意力系数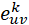 ;节点特征聚合阶段则更加复杂,首先是用softmax计算各个head的attention系数,然后是head内,各边消息中的特征根据attention系数加权进行累加;最后,特征变换阶段将多个head的累加结果拼接起来形成一个完整特征并经过非线性激活。综上,其一层的阶段划分模型如表4所示。
;节点特征聚合阶段则更加复杂,首先是用softmax计算各个head的attention系数,然后是head内,各边消息中的特征根据attention系数加权进行累加;最后,特征变换阶段将多个head的累加结果拼接起来形成一个完整特征并经过非线性激活。综上,其一层的阶段划分模型如表4所示。

表4 GIN一层阶段划分模型列表
(4)GIN
GIN39是结构较为简单的一个GNN模型,其边消息提取和节点信息聚合阶段与GCN相同,分别是直接复制源节点的特征,以及对各边特征做累加。对于节点特征更新阶段,不同于GCN将两个矩阵向量乘法的结果相加,GIN将本节点源特征向量乘了一个可学习的标量系数后,与信息聚合的结果相加,然后通过多层(K层)全连接网络进行变换。综上,其一层的阶段划分模型如表5所示。

表5 GIN一层阶段划分模型列表
未完待续。
3、作者介绍
钟凯,2019年本科毕业于清华大学电子工程系,目前在清华大学电子工程系电路与系统研究所攻读博士学位,在汪玉教授和戴国浩博士后的指导下,主要从事神经网络的量化算法、硬件加速、基于FPGA的加速器开发等工作。
戴国浩,现清华大学电子工程系助理研究员、博士后,分别于2019年和2014年在清华大学电子工程系获得博士与学士学位。主要研究方向为大规模图计算、异构计算、存算一体、虚拟化等,曾获ASPDAC 2019最佳论文奖、DATE 2018最佳论文提名。
4、参考文献
1、 He, Kaiming et al. “Deep Residual Learning for Image Recognition.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016): 770-778.
2、 Hannun, Awni Y. et al. “Deep Speech: Scaling up end-to-end speech recognition.” ArXiv abs/1412.5567 (2014): n. pag.
3、 Silver, D. et al. “Mastering the game of Go with deep neural networks and tree search.” Nature 529 (2016): 484-489.
4、 Battaglia, P. et al. “Relational inductive biases, deep learning, and graph networks.” ArXiv abs/1806.01261 (2018): n. pag.
5、 Krizhevsky, A. et al. “ImageNet classification with deep convolutional neural networks.” Communications of the ACM 60 (2012): 84 - 90.
6、 Staudemeyer, R. and Eric Rothstein Morris. “Understanding LSTM - a tutorial into Long Short-Term Memory Recurrent Neural Networks.” ArXiv abs/1909.09586 (2019): n. pag.
7、 Fan, Wenqi et al. “Graph Neural Networks for Social Recommendation.” The World Wide Web Conference (2019): n. pag.
8、 Rusek, Krzysztof and P. Chołda. “Message-Passing Neural Networks Learn Little’s Law.” IEEE Communications Letters 23 (2019): 274-277.
9、 Fout, A. et al. “Protein Interface Prediction using Graph Convolutional Networks.” NIPS (2017).
10、 Xie, Zhipu et al. “Sequential Graph Neural Network for Urban Road Traffic Speed Prediction.” IEEE Access 8 (2020): 63349-63358.
11、 Gori, M. et al. “A new model for learning in graph domains.” Proceedings. 2005 IEEE International Joint Conference on Neural Networks, 2005. 2 (2005): 729-734 vol. 2
12、 Scarselli, F. et al. “The Graph Neural Network Model.” IEEE Transactions on Neural Networks 20 (2009): 61-80.
13、 Bianchi, F. M. et al. “Pyramidal Graph Echo State Networks.” ESANN (2020).
14、 Bruna, Joan et al. “Spectral Networks and Locally Connected Networks on Graphs.” CoRR abs/1312.6203 (2014): n. pag.
15、 Henaff, Mikael et al. “Deep Convolutional Networks on Graph-Structured Data.” ArXiv abs/1506.05163 (2015): n. pag.
16、 Defferrard, M. et al. “Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering.” NIPS (2016).
17、 Kipf, Thomas and M. Welling. “Semi-Supervised Classification with Graph Convolutional Networks.” ArXiv abs/1609.02907 (2017): n. pag.
18、 Micheli, A.. “Neural Network for Graphs: A Contextual Constructive Approach.” IEEE Transactions on Neural Networks 20 (2009): 498-511.
19、 Atwood, J. and D. Towsley. “Diffusion-Convolutional Neural Networks.” NIPS (2016).
20、 Hamilton, William L. et al. “Inductive Representation Learning on Large Graphs.” NIPS (2017).
21、 Velickovic, Petar et al. “Graph Attention Networks.” ArXiv abs/1710.10903 (2018): n. pag.
22、 Fey, M. and J. E. Lenssen. “Fast Graph Representation Learning with PyTorch Geometric.” ArXiv abs/1903.02428 (2019): n. pag.
23、 Wang, Minjie et al. “Deep Graph Library: Towards Efficient and Scalable Deep Learning on Graphs.” ArXiv abs/1909.01315 (2019): n. pag.
24、 Lerer, A. et al. “PyTorch-BigGraph: A Large-scale Graph Embedding System.” ArXiv abs/1903.12287 (2019): n. pag.
25、 Ma, Lingxiao et al. “NeuGraph: Parallel Deep Neural Network Computation on Large Graphs.” USENIX Annual Technical Conference (2019).
26、 Zhu, Rong et al. “AliGraph: A Comprehensive Graph Neural Network Platform.” Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (2019): n. pag.
27、 Hu, Yuwei et al. “FeatGraph: A Flexible and Efficient Backend for Graph Neural Network Systems.” SC20: International Conference for High Performance Computing, Networking, Storage and Analysis (2020): 1-13.
28、 Yan, Mingyu, et al. “HyGCN: A GCN Accelerator with Hybrid Architecture.” 2020 IEEE International Symposium on High Performance Computer Architecture (HPCA), IEEE, 2020, pp. 15–29. DOI.org (Crossref), doi:10.1109/HPCA47549.2020.00012.
29、 Liang, Shengwen, et al. “EnGN: A High-Throughput and Energy-Efficient Accelerator for Large Graph Neural Networks.” ArXiv:1909.00155 [Cs], Apr. 2020. arXiv.org, http://arxiv.org/abs/1909.00155.
30、 Geng, Tong, et al. “AWB-GCN: A Graph Convolutional Network Accelerator with Runtime Workload Rebalancing.” ArXiv:1908.10834 [Cs], Apr. 2020. arXiv.org, http://arxiv.org/abs/1908.10834.
31、 Kiningham, Kevin, et al. “GRIP: A Graph Neural Network Accelerator Architecture.” ArXiv:2007.13828 [Cs], July 2020. arXiv.org, http://arxiv.org/abs/2007.13828.
32、 Auten, A., et al. “Hardware Acceleration of Graph Neural Networks.” 2020 57th ACM/IEEE Design Automation Conference (DAC), 2020, pp. 1–6. IEEE Xplore, doi:10.1109/DAC18072.2020.9218751.
33、 Zhang, B., et al. “Hardware Acceleration of Large Scale GCN Inference.” 2020 IEEE 31st International Conference on Application-Specific Systems, Architectures and Processors (ASAP), 2020, pp. 61–68. IEEE Xplore, doi:10.1109/ASAP49362.2020.00019.
34、 Zeng, Hanqing, and Viktor Prasanna. “GraphACT: Accelerating GCN Training on CPU-FPGA Heterogeneous Platforms.” The 2020 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Feb. 2020, pp. 255–65. arXiv.org, doi:10.1145/3373087.3375312.
35、 Zhang, Ziwei, et al. “Deep Learning on Graphs: A Survey.” ArXiv:1812.04202 [Cs, Stat], Mar. 2020. arXiv.org, http://arxiv.org/abs/1812.04202.
36、 Bruna, Joan et al. “Spectral Networks and Locally Connected Networks on Graphs.” CoRR abs/1312.6203 (2014): n. pag.
37、 Hamilton, William L. et al. “Inductive Representation Learning on Large Graphs.” NIPS (2017).
38、 Velickovic, Petar et al. “Graph Attention Networks.” ArXiv abs/1710.10903 (2018): n. pag.
39、 Xu, Keyulu, et al. “How Powerful Are Graph Neural Networks?” ArXiv:1810.00826 [Cs, Stat], Feb. 2019. arXiv.org, http://arxiv.org/abs/1810.00826.
上一个: 图神经网络加速器深度调研(中)
近期文章




 商务合作:business@birentech.com
商务合作:business@birentech.com 业务电话:021-68773133
业务电话:021-68773133

商务合作