
贝叶斯方法与深度学习的结合及应用(2)
发布时间:2021-01-23 11:15
摘要
贝叶斯方法是解决数据稀疏、数据样本带有噪音等问题的有效方法,与图论的结合又衍生出具有可解释性的贝叶斯网络,在医疗、生物、系统可靠性和金融等领域都有着广泛的应用。近年来,也有越来越多的研究开始将贝叶斯方法应用到深度学习中,如文献[1]提出了用以贝叶斯方法为基础的概率图与深度神经网络构建具有视觉和任务两个功能模块的系统。有关这方面的更多信息可以参考往期文章概率图模型在深度学习的应用。
继上篇文章贝叶斯方法与深度学习的结合及应用(2)对KDD2020的一篇最新研究工作“A framework for recommending accurate and diverse items using Bayesian graph convolutional neural networks“[2]的研究分析之后,在本篇文章中,我们将结合自己对前沿不确定性与深度学习结合技术的理解,对文[2]中使用的贝叶斯方法进行了更多的深度思考。例如,将文[2]中的贝叶斯方法与主流深度不确定性技术(如MC dropout, ensembling learning)从结果不确定性、计算需求等方面进行了剖析。大量计算是现在深度学习普遍遇到的一个难题,更是贝叶斯方法从理论走向广泛应用的一个技术瓶颈,本文也从并行化计算方面对文[2]进行了深入研究。
概述
论文[2]将最新的图神经网络应用于推荐系统,并将贝叶斯方法分别从模型参数和网络结构两个方面进行了有机整合。
一方面,在模型训练过程中,引入了模型参数先验分布,通过求得模型参数的最大后验估计完成模型训练。与完全依赖于数据的最大似然估计不同的是,最大后验估计依赖于先验分布,因此先验概率的选择也是至关重要。论文[2]选择了高斯分布作为模型参数的先验分布,这是数据分析中常见的选择。
另一方面,贝叶斯方法也用于推荐系统的图神经网络训练的改进。因为有限的数据很可能没有囊括用户在训练数据之外的交互行为,从给定训练数据衍生出的用户-物品交互结构Gobs并不能反映用户的所有交互信息,所以仅基于单一观察到的图Gobs的推荐系统往往会忽略潜在的物品偏好和意图。针对该问题,作者提出了根据用户之间在历史数据中的相似行为推荐其他用户的偏好物品,从而获得用户潜在的物品倾向和意图,这是推荐系统常规的解决思路。在实际应用中,现有的贝叶斯图神经网络是否适用与图结构息息相关,而这又是由具体应用所决定。文[2]的创新之处在于巧妙地借助了node-copy[6]机制提出了一种更通用的生成模型,非常适用于推荐系统应用。其基本思路:根据已知图Gobs,按照合适的概率分布使用node-copy机制采样得到一系列生成图G,使得生成图G中尽可能包含了比Gobs更多样性的物品交互,这也是图采样的主要目的。
基于不确定性的训练方法
在实现图神经网络生成模型的方法上,作者提出了直接和间接两种方法:(1) 根据图Gobs同时训练得到NG个采样图G,最终预测结果由所有训练得到的采样图共同决定;(2) 按照方法(1)进行图采样,但采样图并不用于学习一组模型,而是用于重新定义目标函数,并以此来训练单一模型。下面分别对这两种设计方法进行详细叙述。
直接方法
推荐系统的主要任务是给定训练数据中的用户-物品排序用于确定测试数据中的物品排序。训练数据中的交互信息可由图Gobs完全捕捉,但为了能更好地捕捉未曾在Gobs中出现的交互信息,作者提出根据用户之间的相似性进行采样得到新的交互图G。给定测试数据,所有用户的物品排序任务转换为对采样图G和模型参数的函数求积分,并可按照模型参数和采样图的顺序由内至外进行积分计算,如下式:
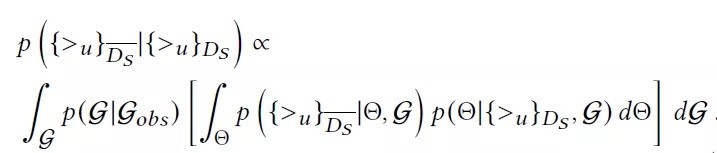
然后,采用蒙特卡洛估计上述积分,预测结果转化为对NG个采样图预测结果的均值计算,如下式所示。其中,公式右边的模型参数是图Gl采用SGD训练后的最大后验估计,其取值依赖于各自的图结构Gl。显而易见,这种多个模型同时训练的方法对计算需求提出了一个非常大的挑战。
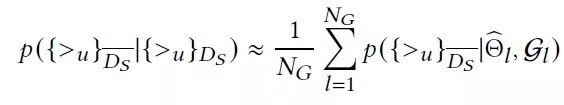
模型训练涉及目标函数定义以及基于目标函数的模型参数优化两个步骤。直接方法可简单地看成是对优化后的NG个模型参数的粗暴聚合,更严格地来说,是对基于最大似然估计的模型预测结果的均值计算,但这并不是最明智的选择。鉴于此,作者另辟蹊径,从目标函数寻得另一个更经济实惠的训练方法。作为目标函数的基本组成项xuij,与其只考虑单个图中的交互信息,作者将考虑范围扩展到NG个生成图,并以平均聚合的方式综合所有交互信息。这种新的方法并没有直接运用贝叶斯方法,可称之为间接方法。
间接方法
如前述,在直接方法中,其潜在的思想是用户有些潜在偏好可能被单一模型所忽略,因此采用同时训练多个模型并对所有模型的物品排序结果求均值,这是常规的贝叶斯深度学习方法。论文[2]创新性地提出以单一模型取代一组模型的训练方法,避免了可能存在的过拟合问题。先以基于ground-truth的图Gobs与直接方法相同的方式得到采样图G。在这一步,采样的实质是为了获得用户潜在的物品偏好,具体反应在变量xuij中,表示用户在物品i和j中偏向i。在直接方法中,xuij的计算是基于单个采样图而言,而间接方法中对所有采样图的用户偏好进行了均值聚合。具体表示为如下式:
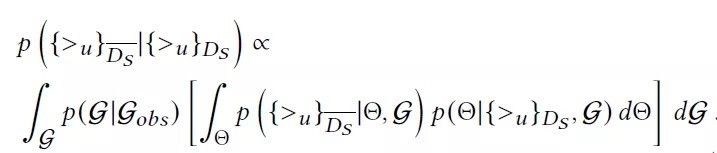
在训练过程中,间接方法只需要对基于上式的目标函数进行优化,当然也是需要先给模型参数赋予先验分布。值得注意的是,上式只应用于单一模型,而不是一组模型。
直接方法与间接方法的异同点可总结为表1。
|
采样图G个数 |
并行计算 |
训练模型 |
|
|
直接方法 |
NG |
支持 |
NG |
|
间接方法 |
NG |
支持 |
1 |
表1: 直接方法vs 间接方法
如表1所示,间接方法的主要优势是将模型训练个数从NG降到了1,文[2]的实验部分也是按照这种方法进行设计。
图神经网络的并行化
推荐系统规模巨大,并行化是提高系统性能必不可少的环节。针对图神经网络结构,也可以从两个方面来实现系统的并行化。
首先,上述的直接和间接方法都包含了一个非常重要的步骤:给定图Gobs,按照一定概率分布生成新的图神经网络。在这里,作者采用了常见的IID(Independently identically distributed)假设,即用户A、B、C两两之间的物品交互相似性是相互独立的,因此每个用户的采样也可以单独分开进行,具体表现在下式,是实现并行化的第一个着手点。

其次,从更宏观层面来说,每个图的采样过程以及后续图中节点嵌入(embedding)表示的更新都是相互独立的,因此也可以并行计算,如图1所示。
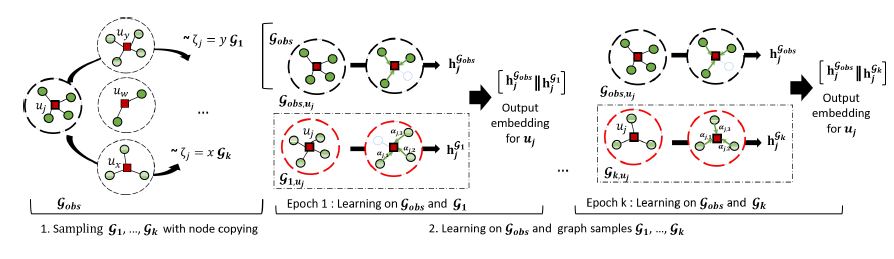
图1:采样图的并行训练
最后,可以将上述两个步骤整合为串行的并行计算:先用一个并行计算完成图采样,然后再用另一个并行计算完成后续的图更新操作。这两个步骤虽然不能颠倒顺序,但是图采样与模型训练在不同的batch上是不交集的,因此可以在batch层面实现并行。围绕此思想,文[2]设计了多线程并行图采样和网络训练的方法。这种多层次的并行计算无疑将充分利用越来越普及的高性能计算的硬件设备,有望大大提高模型训练效率。随着越来越复杂的深度模型(如Switch Transformer)的出现,这种并行设计思想是非常值得借鉴。
扩展思考
论文[2]是贝叶斯方法在推荐系统的最新应用,在模型训练方面提出了直接和间接两种不同的思路。
从本质上来说,直接方法是贝叶斯神经网络的一个典型应用案例,创新在于是将之用于最新的图神经网络结构,充分利用了图结构来挖掘用户之间的潜在关系。其实,这也是学术界用来解决模型不确定性常用的方法,其思想与集成学习(ensemble learning)非常相似。主要区别在于,集成学习在进行多个模型训练时,事先对训练数据进行重排(shuffle)。虽然集成学习的设计思想简单、易于理解,但其在深度学习上的性能往往能超出其他更复杂的模型[8]。这自然引出了一个问题,如果在该系统中采用集成学习,其效果如何?与直接方法相比,其在性能上的差异又如何?
文[2]也创新性地提出了基于单一模型训练的间接方法,其主要思想与广泛应用于贝叶斯神经网络的MC dropout[7]方法不谋而合。传统的dropout是在训练过程中随机地“关掉”每层中的神经元,从而训练得到一组模型。而在MC dropout方法中,这种随机的“开关“操作可以看成是深度高斯进程的贝叶斯近似。在给定模型输入同样的测试数据的情况下,每次运行的模型都需要先按照一定的方法进行采样,从而得到不同的预测结果,而这种预测结果支持并行计算。从这些预测结果的均值可作为最终的预测结果及其方差作为结果不确定性的估计。如果将间接方法与主流的MC dropout方法进行比较,各自的优劣势体现如何?
与现有的确定性方法相比,文[2]中的直接方法能生成多个预测结果,可用于不确定性估计,不确定性估计能更好地捕捉预测结果的取值范围,提供了更广的选择空间,可以广泛应用于如医疗诊断、自动驾驶等高风险领域、主动学习(Active Learning)中的不确定性估计、少样本学习[3]、强化学习[4]、训练数据分布之外检测等,而基于结果不确定性估计是目前不确定性研究的主流方向之一[5],并被广泛应用于计算机视觉、化学等。这又引出了一个值得思考的问题,文[2]是否也可以在不增加现有计算量的前提下也产生不确定性结果呢?这也可能为贝叶斯图神经网络在自动驾驶等领域的应用提供非常宝贵的参考价值。
推荐系统是现在机器学习在工业界得到成功应用的一个典型案例,而大规模训练和推理是实际应用中经常遇到的问题。虽然文[2]在工业界数据集上进行模型评估,与实际应用的数据规模仍然不在同一级别。如何有效实现大规模的贝叶斯图网络训练、推理是模型走出实验室的关键因素之一,尤其是在计算资源非常有限的边缘设备,更是对推理模型计算效率提出了更高的要求。
总结
本文深入分析了基于图卷积神经网络推荐系统中贝叶斯方法的创新运用,重点剖析了文[2]中两种基于用户-物品交互不确定性的的图神经网络训练方法。我们还比较了这两种方法与MC dropout和集成学习等方法的异同,并在扩展部分进行了详细讨论。
由于水平有限,文中存在不足的地方,请各位读者批评指正,也欢迎大家参与我们的讨论。
参考文献
[1]Wang,Hao, and Dit-Yan Yeung. "A survey on Bayesian deep learning." ACM Computing Surveys,2020.
[2]Sun,Jianing, et al. "A framework for recommending accurate anddiverse items using Bayesian graph convolutional neural networks.",SIGKDD, 2020.
[3]Du,Chao, et al. "Exploration in online advertising systems withdeep uncertainty-aware learning." arXiv preprint, 2020.
[4]Blundell,Charles, et al. "Weight uncertainty in neural networks." arXiv preprint, 2015.
[5]Kendall, Alex,and Yarin Gal. "What uncertainties do we need in Bayesian deep learning for computer vision?." Advances in neural informationprocessing systems. 2017.
[6]Pal,Soumyasundar, Florence Regol, and Mark Coates. "Bayesian graph convolutional neural networks using node copying." arXiv preprint, 2019.
[7]Gal,Yarin, and Zoubin Ghahramani. "Dropout as a Bayesian approximation: representing model uncertainty in deep learning."International conference on machine learning. 2016.
[8]Wen,Yeming, Dustin Tran, and Jimmy Ba. "Batch Ensemble: analternative approach to efficient ensemble and lifelong learning."arXiv preprint, 2020.
上一个: 面向大规模图计算的系统优化(1)
近期文章




 商务合作:business@birentech.com
商务合作:business@birentech.com 业务电话:021-68773133
业务电话:021-68773133

商务合作