
动态模型编译优化的挑战及实现分析
发布时间:2021-11-15 07:00
摘要
动态的特征在当前的深度学习网络,特别是自然语言处理领域里,有许多体现,比如:动态的控制流,动态的数据结构及动态的数据张量尺寸等。而现有的神经网络编译器,进行编译优化时(如:算子融合等)往往只能针对静态的模型。如何处理动态模型的编译优化,是当前AI编译器适应当前AI模型发展的重要需求,也是面临的重大挑战。目前这方面的公开工作及研究还比较少,本文从已发表的一些研究成果出发,分析动态模型编译优化过程中的难点及挑战,归纳总结其具体的实现方式,为实现动态模型编译研究实现提供参考。
动态模型介绍
动态模型(Dynamic model)在现今许多先进的机器学习模型中都有所体现。例如:对于变化长度输入数据的LSTM (Long Short-Term Memory)模型,由于其迭代的长度不确定,从而导致计算的控制流是动态的;对于语义识别等领域引入的treeRNN (treeLSTM),其输入数据结构也是动态的,同样也引入了动态的递归计算行为,如下图1所示。这些动态模型,在控制流、数据结构及数据形状等方面的不确定性,给编译器的编译性能带来了极大的挑战。
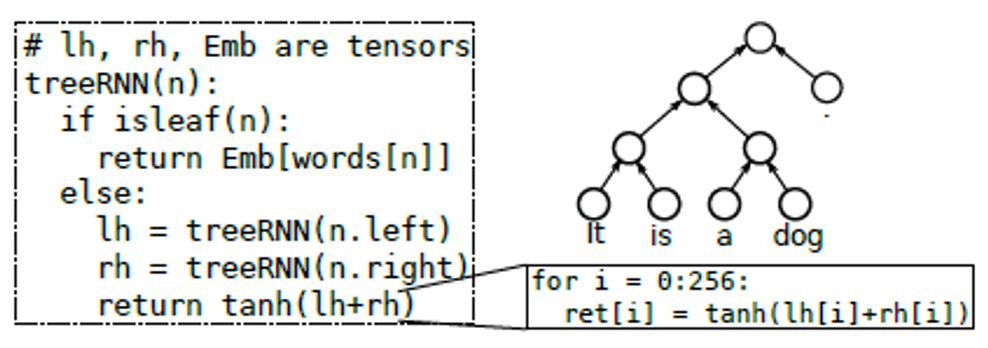
图1 treeRNN递归模型示意图[1]
当前,已有的静态编译器的编译流程包括:首先,计算模型被分解成一个个计算子图,再进一步下降成更具体的计算行为或存储行为的operation node,这个过程中,编译器可以根据子图及operation的行为及数据形状,进行一些编译优化(如:fuse),来减少访存的开销及提高计算效率;然后,通过Codegen工具分别生成host及device侧的高性能可执行代码;最后通过Runtime,按照顺序一个个调用operation节点,完成计算。
而对于动态模型的编译,已有的静态编译方式会遇到很多问题,比如编译过载、存储复用、pipeline优化、部署复杂等问题。因而,要实现对动态模型的高性能编译,需要进行针对性的改进,主要包括:
1.建立一个完整的动态行为算子的中间表示(IR: Intermediate Representation),这种中间表示方式可以完整承载动态算子的信息,为编译器的后续编译提供基础;
2.在算子的动态信息条件下,同样进行和静态信息类似的优化策略,比如:算子融合,存储管理等机制;
3.建立一个高效的Codegen及Runtime联合机制,来支持动态模型的高性能可执行代码的生成及运行。由于动态模型的数据及结构只有在Runtime阶段才能确定,因而Runtime及Codegen需要生成复杂的dynamic infer逻辑。且由于动态模型的计算行为会更复杂,需要Runtime提供更为复杂的schedule行为。
为了应对这些挑战,动态模型的编译器也需要从多个方面,相对静态编译器做出一定的改变,来支持完成高性能的编译。
动态模型编译的实现
目前支持动态模型的编译器工作还比较少,系统性的研究理论也不多。本节中,我们主要结合两个最近发表的支持动态模型编译的论文,来分析动态模型的编译实现。
1. Nimble
Nimble[2]宣称是第一个公开发表的支持动态模型的端到端的神经网络编译器。其基于TVM 0.6框架,定义了一套支持动态shape的数据中间表示(IR),开发了一系列的面向动态行为的优化方法,建立了一个基于虚拟机的轻量级可移植的Runtime,支持动态模型的运行,在常用的动态模型的编译中,有比较好的效果。
Nimble编译器的架构,如下图2所示。
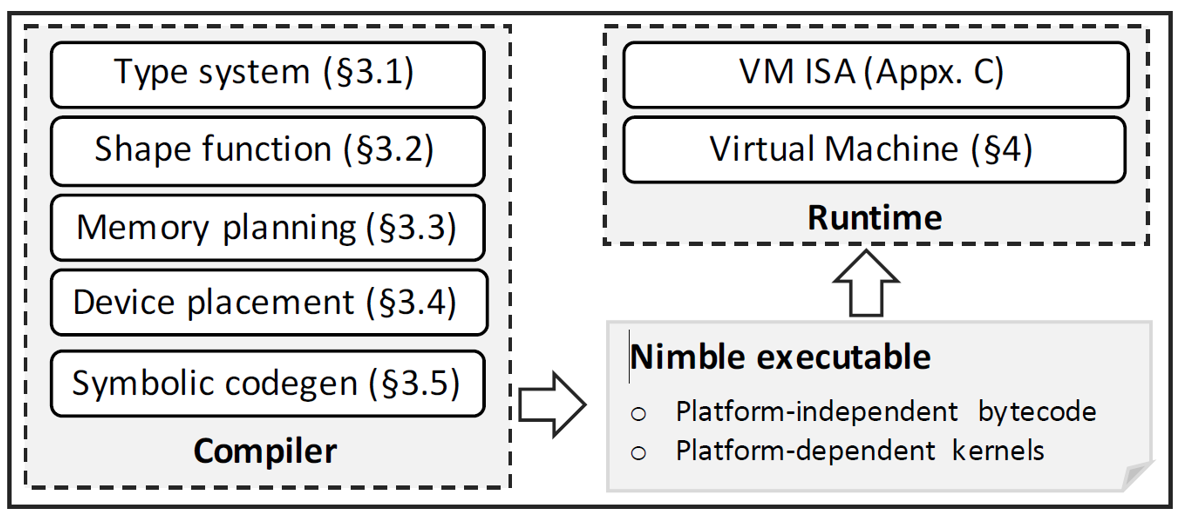
图2 Nimble编译器的架构[2]
其主要的结构包括:
-
Type system: 扩展了“AnyType”等类型及中间表示(IR),使得可以支持算子动态shape的表示。并且强化了算子的type relation及constraint表示,为动态算子的优化提供更好的支持;
-
Shape function:为动态算子提供尺寸计算,分为三类:data independent(与输入数据值无关), data dependent(与输入数据值有关), upper bound(与输入数据尺寸及数据值有关)。从而可以提供处理时所需要分配的内存大小的信息。
-
Memory planning:已有的深度学习编译器,在函数层面隐藏了存储分配的信息,而Nimble增加了明确目标(target)的表示,使得memory分配更加明确。据此,常用的memory 优化方式(如:memory合并,liveness分析,图着色算法等)也可以用在动态模型中。
-
Device Placement:在异构计算平台(host-device)中,动态模型相比于静态模型,会有一些额外的计算发生在host侧(如:shape function计算),因而合理放置IR node,减少host与device之间的同步交互至关重要。Nimble在该阶段引入了device_copy node来表示跨平台的数据交互,并通过并查集(union-find)的方式,实现对所有node标记具体的device placement。
-
Symbolic Codegen:相比于静态的编译器,动态编译器的信息是不固定的,因而Codegen需要支持用变量符号表示的不固定信息的node,生成相应的高性能可执行代码。
-
Runtime:最后生成的可执行代码通过Runtime调用目标硬件完成运行。静态模型的Runtime只需要提供一个串行的执行器,其遍历输入的数据流计算节点图,按照顺序派发operators计算任务即可。动态模型,由于有更为复杂的data shape计算,以及存储行为,其任务schedule及host-device交互也更复杂,Nimble是通过定义了一个虚拟机的方式解决这种Runtime复杂调度的问题。
总体而言,Nimble编译器的编译过程为:首先,接收前端编译器的输入模型,转换成其特定的支持动态模型的中间表达(IR),再通过其定义的一系列支持动态模型的优化策略,将IR编译成一个可执行代码,该可执行代码包含了平台无关的bytecode(将在host侧的虚拟机中运行),以及平台相关的kernel code(将在device侧中运行),最后加载该可执行代码到一个VM-based的Runtime,完成运行。
Nimble的测试中,其benchmark采用了LSTM,Tree-LSTM,BERT三种动态模型。与PyTorch, DyNet, TensorFlow Fold等目前支持动态图编译的编译器的性能进行了比较,结果都有一定程度的提升。
2. DISC
DISC[3]是阿里团队基于MLIR发布的一款支持动态shape编译的编译器。其基于对HLO Dialect的扩展,定义了一个支持动态shape表示的方言-DHLO,并增加及扩展了许多已有的优化path来支持动态shape的优化。
DISC编译器的架构,如下图3所示。
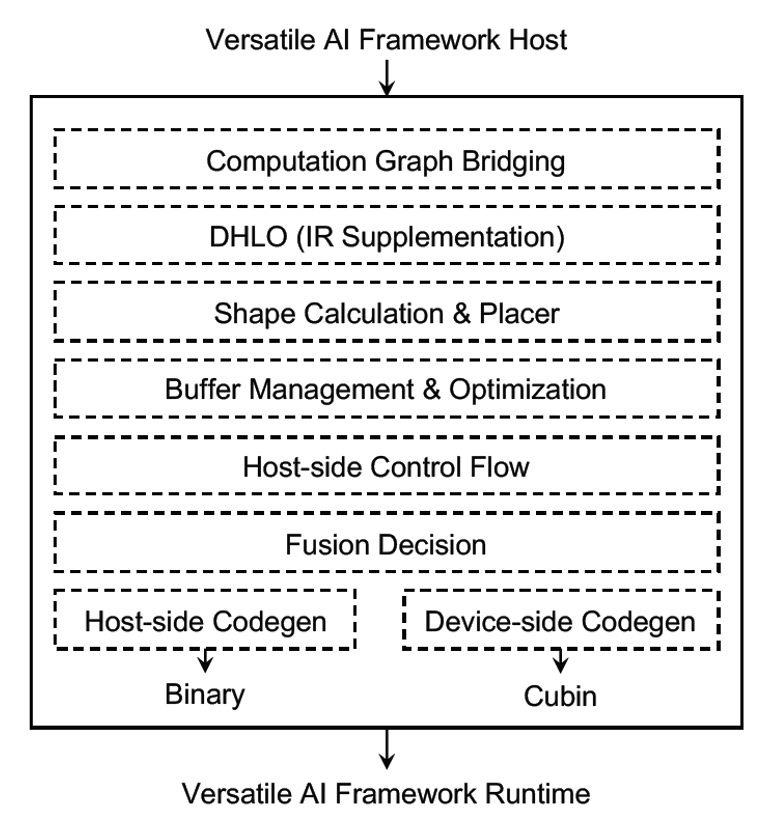
图3 DISC编译器框架示意图[3]
其主要的结构包括:
-
Computation Graph Bridging:用来承接多个AI前端平台(如:PyTorch, TensorFlow),编译下降过来的计算图;
-
DHLO:基于XLA HLO Dialect,扩展形成了DHLO Dialect,可以完备地支持Operation的动态形状;
-
Shape calculation & Placer:DISC将shape计算与数据处理的编译分开。Shape计算放在host侧,而tensor数据的处理放在device侧;
-
Buffer Management & Optimization:DISC在此阶段会根据计算的shape,进行buffer allocation,并且通过buffer的life-time分析及shape信息分析,进行buffer free及reuse优化;
-
Host-side Control Flow:相比较静态shape,动态模型的host侧的控制逻辑,在kernel launch的管理,device的管理,以及kernel-host之间的交互等方面也会更复杂。Host侧的控制逻辑在此阶段产生,可以减少一些编译的过载,并且提供更多的host-device共同优化的机会。
-
Fusion Decision:该阶段的operation在host/device的placement已经明确,编译器根据对operation之间的shape传递及shape 限制的分析,得到更明确的shape关系信息,从而来决定对operation的fuse优化。
-
Codegen:最后将产生相应的host和device的可执行二进制文件。
DISC与Nimble的编译流程有许多相似的地方,事实上论文里也有大量与Nimble的比较。总体而言,都是:首先定义了一个完备的支持动态模型的中间表示(IR);然后再通过shape计算及buffer管理模块,实现对动态形状存储的分配;然后再合理放置node到host及device侧,再通过Codegen产生相应的可执行代码;最后,通过Runtime完成计算。所不同的是,Nimble基于TVM软件架构扩展,并且增加了一个虚拟机,将host侧的复杂调度,分布在host程序及虚拟机中;而DISC则是基于MLIR软件框架[4]开发,看上去其在支持动态模型的IR扩展方面,及相关的优化方面要更轻松一些,其也将host侧的调度都放在host侧的控制逻辑中,从而使Runtime的复杂度没有像Nimble那么高。
结论与思考
本文主要对动态模型的编译做了一些基本的介绍,包括动态模型的基本概念,以及动态模型编译面临的挑战,同时也简要分析了已经公开发表的两个支持动态模型编译的框架Nimble和DISC。本人也希望通过本文,可以让读者对动态模型编译的实现过程有所了解,从中得到一点启发。
由于水平有限,文中存在不足的地方请各位读者批评指正,也欢迎大家一起参与我们的讨论。
参考文献
[1] Pratik Fegade, et, al. CORTEX: A Compiler for Recursive Deep Learning Models.
[2] Haichen Shen, et, al. NIMBLE: Efficiently Compiling Dynamic Neural Networks for Model Inference, 2021.
[3] Kai Zhu, et, al. DISC: A Dynamic Shape Compiler for Machine Learning Workloads, 2021.
[4] MLIR:https://mlir.llvm.org/
上一个: GAN在因果推理中的应用研究
下一个: 大型医疗图像的图表示:百亿级像素信息提取
近期文章




 商务合作:business@birentech.com
商务合作:business@birentech.com 业务电话:021-68773133
业务电话:021-68773133

商务合作