
Transformer霸榜,点积自注意力是否不可替代?
发布时间:2021-12-13 07:00
摘要
自注意力机制使Transformer成为可解释性较强的模型之一,基于query-key的点积自注意力作为自注意力机制的核心组件看起来是必不可少的:点积自注意力使成对的token被完全连接,并且能够对长距离依赖的信息进行建模。但是点积自注意力的计算真的是必须的吗?越来越多的工作深入探索自注意力,并给出了否定的回答。本文从点积自注意力的原理出发,并以两篇参考文献以例,重新思考自注意力机制,进一步对点积自注意力的可替代性展开讨论。
点积自注意力
Transformer 模型的核心为自注意力机制,同时点积自注意力是最必不可少的核心组件。我们通过下面的公式[1]理解点积自注意力的含义:
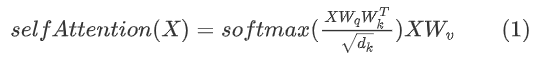
具体说来,在点积自注意力中,通过对同一个输入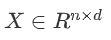 经过不同的投影矩阵
经过不同的投影矩阵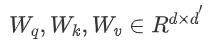 得到
得到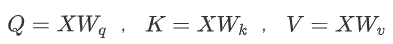 。为了方便后文理解,这里统一点积自注意力及权重的计算表达式:
。为了方便后文理解,这里统一点积自注意力及权重的计算表达式:

其中,A由query、key点积得到的注意力权重矩阵B在序列长度维度上进行归一化得到的[2]。
点积自注意力是如何提供了强大的建模能力呢?考察其几何含义上:基于query-key的点积计算确定了序列中每一个token相对于所有其他token的重要程度,来学习自对齐矩阵。点积自注意力机制可以理解为一个模拟基于内容的检索过程,过程的核心是成对token间的交互。
然而,特定于实例的交互容易使注意力权重产生自由波动,并且相对于整个序列来说依旧表征局部的信息变化,缺乏一致的全局语境。越来越多的工作深入探索自注意力并发现:自注意力旨在生成自对齐矩阵;通过query-key点积计算自注意力可能是不必要的,甚至可以说完全不需要基于内容的自注意力。下面本文将以两篇参考文献以例,重新思考自注意力机制,分析点积自注意力的可替代性并解释文献中自对齐矩阵的生成方式。
合成器模型
Google Research提出了一种合成器模型[3]。该模型直接合成自对齐矩阵,无需标准自注意力中成对token的点积交互。论文中介绍了四种合成模式:全连接合成器、随机合成器、分解全连接合成器和分解随机合成器,下面将对这四种合成模式展开分析。
全连接合成器
仔细思考公式(1)和(2)可以发现,注意力权重矩阵的计算过程本质上是从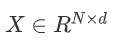 (X表示N个token,每个token的维度为d)的输入得到
(X表示N个token,每个token的维度为d)的输入得到 的过程。若不采用成对token的点积交互,一种简单的方法是通过全连接层来进行维度间的变换。论文中提出了全连接合成器,即两层全连接层加上线性整流激活函数(ReLU)生成B矩阵。如图1(b)所示,这一步骤中,序列中的每个token都是独立计算的,token之间并不产生任何交互。最后,注意力权重矩阵经过Softmax操作与value向量相乘得到最终的注意力输出。上述过程与点积自注意力模型相似,虽然全连接合成器也利用局部样本信息,但作者用全连接层替换掉了标准自注意力中的query-key点积计算。
的过程。若不采用成对token的点积交互,一种简单的方法是通过全连接层来进行维度间的变换。论文中提出了全连接合成器,即两层全连接层加上线性整流激活函数(ReLU)生成B矩阵。如图1(b)所示,这一步骤中,序列中的每个token都是独立计算的,token之间并不产生任何交互。最后,注意力权重矩阵经过Softmax操作与value向量相乘得到最终的注意力输出。上述过程与点积自注意力模型相似,虽然全连接合成器也利用局部样本信息,但作者用全连接层替换掉了标准自注意力中的query-key点积计算。
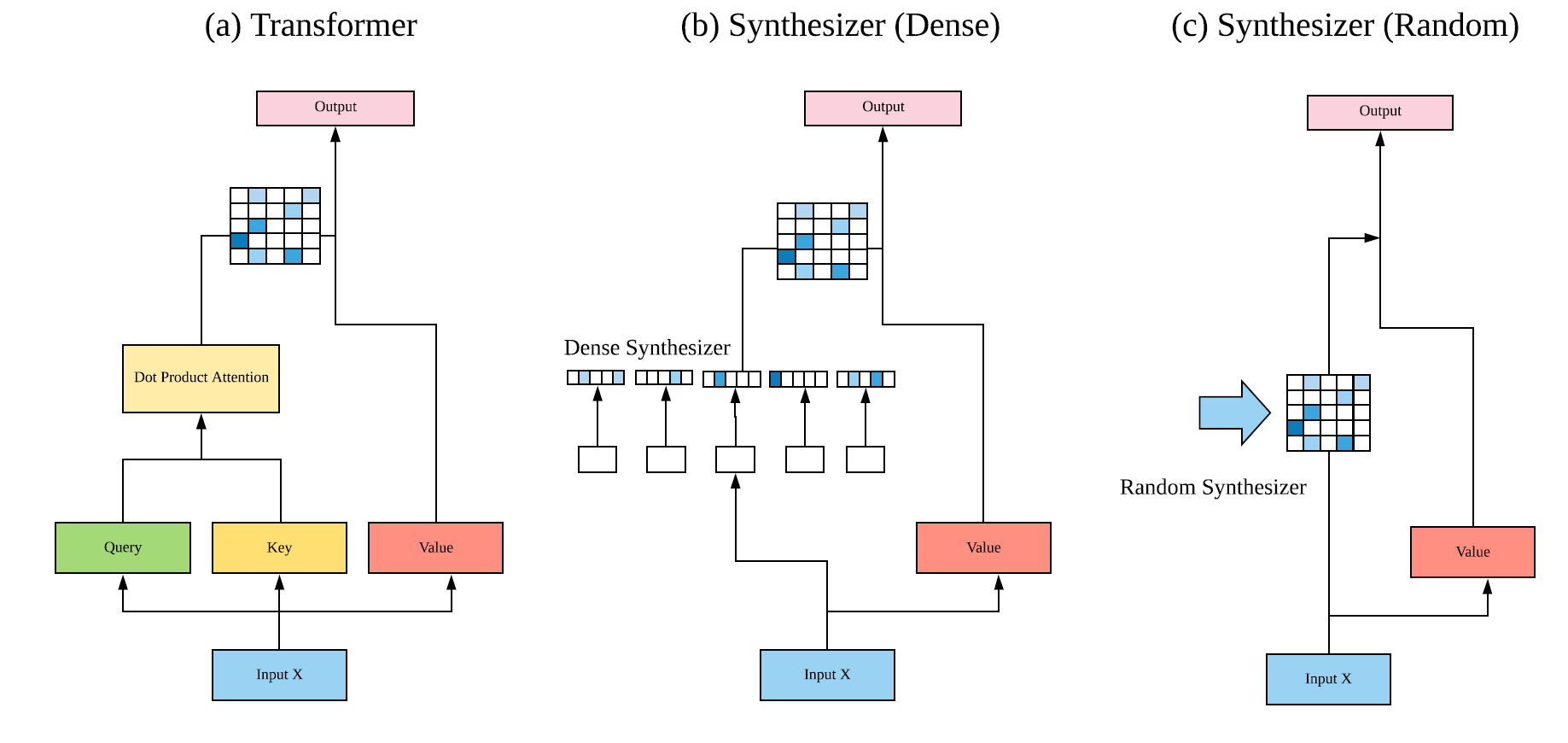
图1 合成器结构[3]
随机合成器
如图1(b)所示,为了得到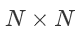 大小的注意力权重矩阵B,全连接合成器将序列中的每个token进行独立映射。在此基础上,作者进一步提出了随机合成器(图1(c)),随机合成器通过随机初始化得到注意力权重B,B可以选择随训练更新或不更新。该合成器模型既不依赖于成对的token也不依赖于内容,且过程中利用全局样本信息,学习一种任务式的对齐方式。
大小的注意力权重矩阵B,全连接合成器将序列中的每个token进行独立映射。在此基础上,作者进一步提出了随机合成器(图1(c)),随机合成器通过随机初始化得到注意力权重B,B可以选择随训练更新或不更新。该合成器模型既不依赖于成对的token也不依赖于内容,且过程中利用全局样本信息,学习一种任务式的对齐方式。
分解模型
全连接合成器生成权重矩阵的过程为网络添加了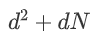 的参数,而随机合成器在此过程为网络添加了
的参数,而随机合成器在此过程为网络添加了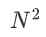 的参数。如果在序列很长的情况下,上述两种模型均具有很大的参数量。因此,作者针对两种合成器分别提出了对应的分解模型来减少参数量及防止过拟合。
的参数。如果在序列很长的情况下,上述两种模型均具有很大的参数量。因此,作者针对两种合成器分别提出了对应的分解模型来减少参数量及防止过拟合。
分解全连接合成器模型针对可能过大的序列长度N,先经过全连接合成器生成两个矩阵记为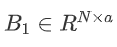 和
和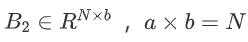 。然后将B1中表示token的向量重复b次,B2中表示token的向量重复a次后,做元素积。上述过程可将两个分解矩阵恢复到B,减小模型参数量。类似地,分解随机合成器模型先经过随机合成器生成两个矩阵记为
。然后将B1中表示token的向量重复b次,B2中表示token的向量重复a次后,做元素积。上述过程可将两个分解矩阵恢复到B,减小模型参数量。类似地,分解随机合成器模型先经过随机合成器生成两个矩阵记为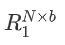 和
和 。再将
。再将 与
与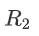 的转置做外积恢复到B,同样减小了模型参数量。表1将上述合成器的特性做了汇总,更多细节见表1所示:
的转置做外积恢复到B,同样减小了模型参数量。表1将上述合成器的特性做了汇总,更多细节见表1所示:
表1. 合成器模型概述[3]
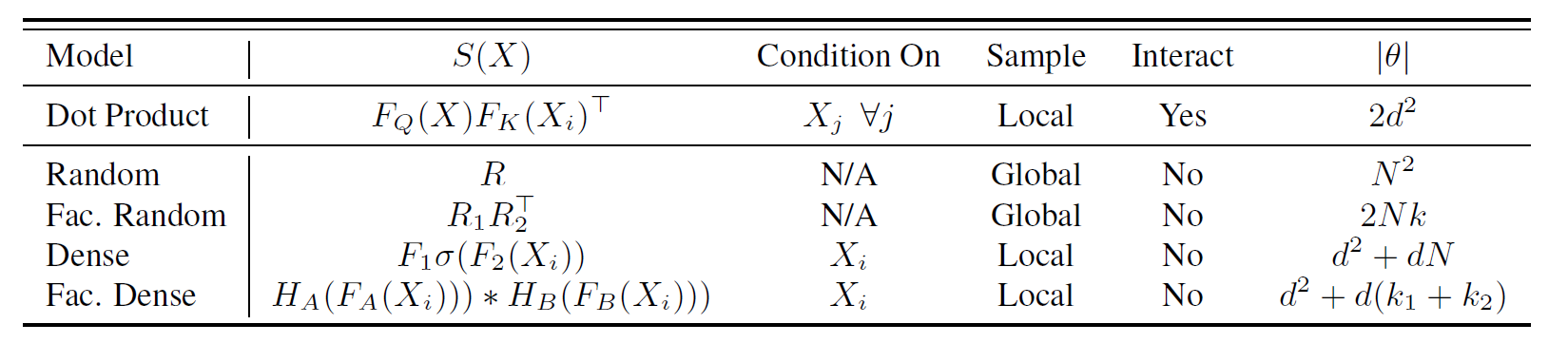
由表1可知,上述四种合成器模型都代替了query-key的点积交互,且模型参数量都相对减少了。
实验结果
此文提出可将上述合成器模型和点积方法以加和的方式组合使用生成自对齐矩阵。作者分别在机器翻译、语言模型、文本生成、多任务自然语言处理等任务上进行了实验。在机器翻译和多任务自然语言处理等任务上,混合合成器(Random + Dot)模型[2]与其他模型相比,取得最好的效果。两个分解方法虽不如混合模型取得更多的提升,但在一定程度上减少了模型参数量。
然而,对于文本生成任务而言,合成器的各个模型表现不一。与一些预训练模型相比,合成器模型在单一性的任务上表现良好,但是训练出的模型泛化性差,迁移能力不足。
固定编码自注意力
点积自注意力本质上关注局部领域内token信息。基于此,You等人[4]提出用固定编码自注意力来代替可学习的点积自注意力。该方法无需点积注意力或基于内容的注意力。实验发现,用高斯分布代替编码器和解码器中的自注意力对机器翻译的结果几乎没有影响,并且使用高斯分布可以还略微提高推理速度、节省内存。
固定编码高斯自注意力
由上文点积自注意力原理可知:第i个token的自注意力权重是通过查询词向量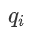 和所有的键向量
和所有的键向量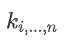 点乘得到的。You等人提出使用以查询词位置i - 1、i 或i + 1 为中心的高斯分布代替点积自注意力权重。高斯分布从几何含义上刻画序列中第i个token相对于序列中所有其他token的重要程度(局部窗口内,与查询词
点乘得到的。You等人提出使用以查询词位置i - 1、i 或i + 1 为中心的高斯分布代替点积自注意力权重。高斯分布从几何含义上刻画序列中第i个token相对于序列中所有其他token的重要程度(局部窗口内,与查询词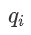 相邻位置的重要程度较高)。公式(3)表示计算固定编码高斯注意力公式:
相邻位置的重要程度较高)。公式(3)表示计算固定编码高斯注意力公式:
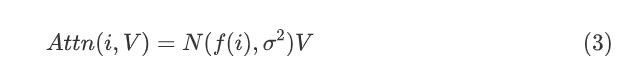
固定编码自注意力本质上是求值向量的加权平均。公式(3)中高斯分布代替了成对token间的点积交互,且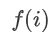 的均值和标准差均为输入X完全无关超参量。以查询词“to”为例,图2表示每个头中的注意力权重都是在局部窗口内以不同token为中心的高斯分布。
的均值和标准差均为输入X完全无关超参量。以查询词“to”为例,图2表示每个头中的注意力权重都是在局部窗口内以不同token为中心的高斯分布。
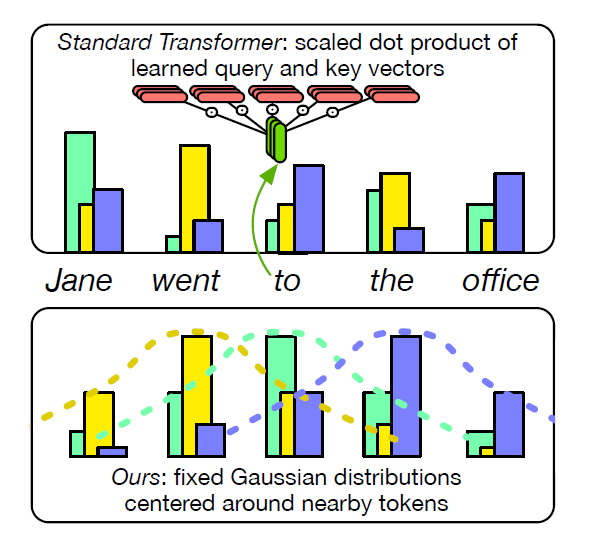
图2 给定查询词“to”,三个自注意力头中的可学习的点积自注意力(上)以及固定高斯注意力(下)[4]
实验结果
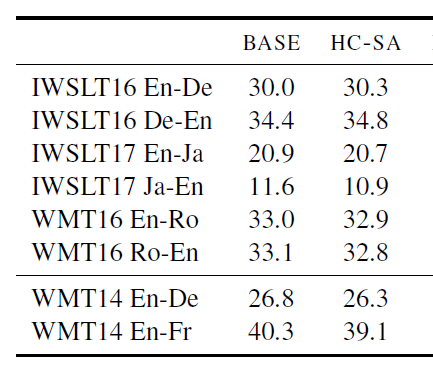
此文提出了固定编码自注意力,它虽然不需要学习任何参数,其性能仍可以与点积自注意力相媲美。在IWSLT16 En-De[5]及其他机器翻译数据集上,编码器和解码器中具有固定编码自注意力的Transformer(HC-SA)与具有点积自注意力的Transformer(BASE)相比,获得几乎相等的BLEU 分数[6,7]。其最佳验证结果是将编码器自注意力权重替换为以i - 1和i + 1为中心的高斯分布,解码器自注意力权重替换为以i - 1和 i 为中心的高斯分布。实验发现,使用高斯分布可以还略微提高推理速度、节省内存。
表2 BLEU分数在不同数据集对HC-SA和BASE进行比较[4]
结论与思考
Google提出了一个无需计算点积注意力的合成器模型。在机器翻译、语言建模和对话生成等多个任务上,合成器注意力与基于点积自注意力的Transformer(BASE)相比,性能表现优秀。在对话生成任务上,成对token间的点积交互反而降低性能。如此看来,自注意力机制中点积自注意力并非不可替代的。
You等人提出的HC-SA之所以能获得与BASE相似的性能,我们认为前馈神经网络层(FFN)发挥了重要的作用,FFN可以学习到固定编码自注意力的损失并补偿。此外,文中实验还证明了,当采用固定编码交叉注意力时,机器翻译的性能会大幅度下降。我们推测固定编码交叉注意力的失败可能是因为解码器的前馈层不够强大,无法补偿固定编码器交叉注意力的信息损失。
本文以点积自注意力的原理出发,并以上述两篇参考文献以例,重新思考自注意力机制。我们发现虽然点积自注意力提供了强大的建模能力和可解释性,但在一些任务中成对token的点积交互并不是必须的。不论是Google Research 提出的可直接合成自对齐矩阵的合成器,还是You等人提出的固定编码自注意力,在多种任务上都表现良好。并且于模型参数量和推理速度而言,非点积自注意力也具有明显的优势。不得不说,无需点积或内容的自注意力是对自注意力机制的深刻认识和突破。
但合成器模型、固定编码自注意力、点积自注意力本身没有绝对的优劣,三者表现与具体的任务相关。为何三者在不同任务中表现存在明显差异?它们分别适合于哪些文本任务?在计算机视觉领域是否同样适用?其背后的原理值得进一步挖掘和探索。
参考文献
[1] Vaswani, A., Shazeer, N.M., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., & Polosukhin, I. (2017). Attention is All you Need. ArXiv, abs/1706.03762.
[2] Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. arXiv preprint arXiv:1910.10683, 2019.
[3] Tay, Y., Bahri, D., Metzler, D., Juan, D., Zhao, Z., & Zheng, C. (2021). Synthesizer: Rethinking Self-Attention in Transformer Models. ArXiv, abs/2005.00743.
[4] You, W., Sun, S., & Iyyer, M. (2020). Hard-Coded Gaussian Attention for Neural Machine Translation. ACL.
[5] Cettolo, M., Jan, N., Sebastian, S., Bentivogli, L., Cattoni, R., & Federico, M. (2016). The IWSLT 2016 Evaluation Campaign.
[6] Voita, E., Talbot, D., Moiseev, F., Sennrich, R., & Titov, I. (2019). Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned. ACL.
[7] Michel, P., Levy, O., & Neubig, G. (2019). Are Sixteen Heads Really Better than One? NeurIPS.
上一个: 基于Object Query的机器视觉新思路: DETR及发展
下一个: 视觉神经场:NeRF研究的新视角
近期文章




 商务合作:business@birentech.com
商务合作:business@birentech.com 业务电话:021-68773133
业务电话:021-68773133

商务合作