
Kubric:高效地合成视觉数据集
发布时间:2022-05-02 07:00
摘要
随着机器学习的发展,数据集的重要性越来越凸显。然而收集大量带标注的图像或者视频数据成本高昂。而使用合成的数据集则成本低,收集方便,且由于标注信息准确,高度可控,从而使得其成为一种训练大规模深度学习模型的有效手段。本文将围绕计算机视觉数据集的合成问题,介绍近期出现的三维视觉数据集的合成工具Kubric,并展示其在深度学习如NeRF模型评估等任务的应用案例。
引言
数据集的重要性伴随着监督学习的发展越来越凸显。为了训练大规模的机器学习或者深度学习模型,尤其是计算机视觉相关的任务,往往需要大量的标注数据。然而,收集大量图像或者视频数据,并手工地去标注,成本非常高昂。一方面,标注的质量存在一些偏差,例如图像的边界不容易分割;另一方面,手工标注大量的视频几乎是一件费时费力的任务,例如标注视频的光流信息、物体的深度信息。
通过合成虚拟的数据,来生成计算机视觉数据集是一种有效的解决方案。可以事先创建好一个三维场景,根据不同的需求,最终由渲染引擎将场景渲染出来。由于三维场景是预先建模的,所以整个虚拟场景的信息是完全已知的,于是输出标注信息就会变得非常容易。例如想要知道两个对象之间的空间位置关系,可以从场景数据信息中直接读取。而如果需要知道某个像素来自于哪个对象,可以从渲染信息得到。如果需要获得一个新视角的图像也很容易,只要调整虚拟摄像机的角度就可以重新渲染出一幅新的图像。
可以设想自动驾驶的场景,为了训练自动驾驶模型,通常需要大规模的视频图像数据集。而在人工构建的虚拟驾驶场景下,场景中的车辆、行人、信号灯等都可以任意的控制,并调取其内部信息,从而可以自由地生成多种不同天气和照明状况的数据,并附带着丰富的标注信息。
总的来说,相比于人工标注的数据集,合成数据具有很多优点。它成本更低,收集更加方便,标注信息更加准确,并且具有高度可控性,能够生成丰富的数据集。它不仅可以生成在现实场景中难以获取的数据信息,还可以避免现实场景下的安全性、隐私性等问题。针对合成数据的工作已有很多,读者可以参考相关专著[1]。
本文将围绕三维图像的合成问题,介绍近期出现的三维视觉数据集合成工具Kubric [2]。与生成对抗网络GAN方法是不同的是,该工具完全由先验知识(物理仿真引擎和图形渲染引擎提供先验)来构建三维虚拟场景。下文将介绍Kubric工具的基本组成结构,使用方法和简单的脚本编写方式,最后展示其在计算机视觉任务上的一些应用。
Kubric工具
Kubric是一个用于生成视觉数据集的工具,它是由Google Research在近期推出的一款开源的Python包[2]。它主要针对的是现有的数据集生成工具易用度不高,数据生成质量偏低,通用程度不高等问题。Kubric通过内部集成已有的物理仿真引擎PyBullet与渲染软件Blender,通过封装后的Python接口,简化了数据集生成的流程,提升了图像视频数据的生成质量,使得数据集的生成方式具有更强的通用性,易用性和可复现性。由于Kubric支持在数千台机器上无缝运行大型作业,所以它能够生成TB数量级的视觉数据集。另外它还集成了一些三维场景的虚拟资产,从而方便了用户的使用。
这里对其集成的软件作进一步的介绍。其中的物理仿真组件PyBullet, 是开源的物理引擎Bullet 的Python语言的封装,主要用于机器人仿真和机器学习。而图像渲染组件Blender则是开源的三维图形建模软件,内置有基于物理的渲染器Cycles和光栅化渲染器Eevee,其中Kubric调用的是基于物理的渲染器Cycles,因此渲染的图像将更加真实。由于PyBullet和Blender提供了完善的Python接口,因此Kubric可以很好地将二者集成为Python库。
从整体的设计框架来说,Kubric将视觉数据集的生成流程分为三个部分:场景构建、物理仿真、图像渲染。其主要的框架如下图:
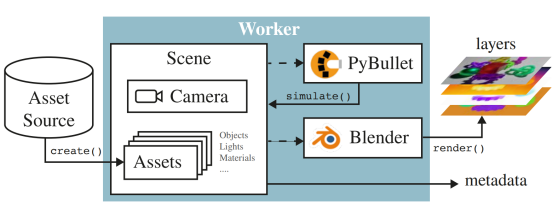
图1. Kubric流程示意图( 引自文献[2] )
从上图可以看到,场景构建对应了框图中的Scene,物理仿真对应着PyBullet,而三维渲染对应着框图中的Blender。而场景(Scene)包含了照相机(Camera)以及虚拟资产(Assets)两个内容。场景构建完成后,如果场景中包含有需要仿真模拟的物体,则将场景数据传递给PyBullet,由PyBullet进行仿真(Simulate)后将信息再传回场景。而最后的场景中待渲染的数据将发给Blender软件,由Blender中Cycles渲染得到最终渲染结果,并附带有所需的标注信息。作为最终输出结果展示,可参考下图:

图2. Kubric渲染结果与标注信息( 引自文献[2] )
可以从图中看出,最终生成的是具有较高真实度的视频数据,而且标注数据包含物体分割信息、物体深度信息、物体坐标信息、表面法向信息(Surface normals),以及光流(Optical flow)信息。
接下来是Kubric的具体使用方式。Kubric的安装比较方便,官方提供了一个Docker镜像,用户只要使用命令 “docker pull kubricdockerhub/kubruntu” 即可配置包含有Pybullet与Blender的环境。该工具在代码层面上的使用流程可以分为四个部分,如下图是生成静态场景数据的方式:

图3. Kubric静态场景构建代码
静态场景主要分为这步骤:1) 创建场景并将渲染器连接到场景上;2)在场景中加入物体,并配置光源和相机。这样静态的场景就构建完成了;3)之后可由渲染器产生.blend文件(.blend是Blender的默认文件格式)并渲染出结果。
对于动态场景,只需要在场景中连接物理仿真器PyBullet,并配置帧率信息,再在场景中加入待仿真的物体,启动仿真器后即可生成动态场景的数据。
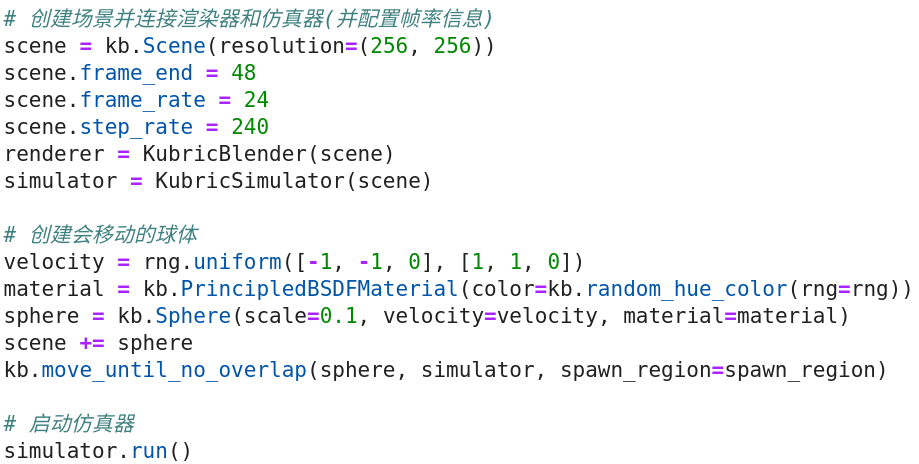
图4. Kubric动态场景构建代码
以上是Kubric工具的使用示例,读者可以进一步查阅具体文档。Kubric论文中共展示了13个视觉数据集生成任务,这里将摘取三个使用案例作简要的介绍。
使用案例
Kubric生成的数据集可用来评估NeRF模型的健壮性(Robustness)。神经辐射场(NeRF)是一种有效的生成逼真的多视角合成方法,在之前的公众号中已多次提及。然而为了评估训练出来的神经辐射场的效果,往往需要一些数据来做进一步的评估。而Kubric工具恰好适合这部分的工作。例如,如果我们获取的多视角数据中,不同视角下的场景有一些偏差,将导致训练出来的模型不够健壮。如下图,在场景中加入一些破坏静态原则的数据,如Teleport或者Jitter方式,就可以评估出NeRF-L1 [3] 与NeRF-L2 [4] 两种模型的训练效果的差异(L1比L2更具有健壮性)。
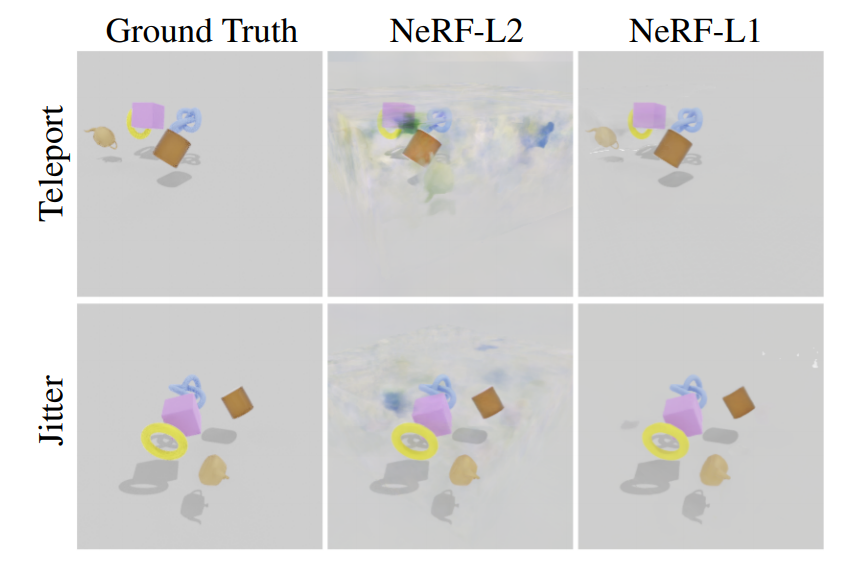
图5. Kubric生成的数据集用于评估NeRF模型( 引自文献[2] )
Kubric生成的数据集可以用来补充真实的人体姿态数据。有关人体姿态的数据集往往具有抽样偏差,例如一些常见但并不美观的人体姿态数据很难收集到,因此可以通过数据生成器来生成更多平衡的数据,另外由于是生成数据,所以也间接地克服了数据的版权和隐私问题。下图是生成的人体姿态数据的展示,其中左侧是合成数据,右侧是真实采集数据。

图6. Kubric生成的人体姿态数据(左侧是生成数据,右侧是真实数据)( 引自文献[2] )
Kubric生成的数据集相比于先前的工具具有更高的运动真实性。对于视频数据,很难标注出真实场景的光流信息,因此光流估计是计算机视觉中第一个依靠合成数据来评估的任务。而现有的合成数据的方式如FlyingChairs [5] 和AutoFlow [6] 等都是基于二维的分层模型,在渲染上缺乏三维运动的真实感,如下图。Kubric生成的数据集可以使训练出来的模型具有更好的表现。

图7. Kubric生成的数据与其他方式的对比( 引自文献[2] )
总结与展望
作为一个视觉数据集生成的Python工具,Kubric使得低成本生成计算机视觉数据集成为可能。一方面,它能够生成高质量的合成数据,另一方面,也使得构建视觉数据集的流程变得简易。当然由于Kubric也面临的一些挑战,当合成的数据与真实的数据具有一定的偏差,那么为了使得训练的模型能够应用到真实的场景中,还是需要收集真实的场景的标注数据,且需要迁移用合成数据训练的模型。另外,由于合成数据依赖构建的三维场景,如果三维场景本身具有一些缺陷,那么生成的数据集势必会引入这些缺陷;最后,在生成数据集之前,也需要花费较多的成本用来设计特定的三维场景。
另外,值得期待的是,由于Kubric集成了三维建模软件Blender 和物理仿真工具PyBullet,而物理引擎和渲染引擎工具本身就具有非常多内置的功能,例如流体的仿真与渲染,布料仿真和渲染等(虽然Kubric目前还不支持),都可以进一步地用来生成更加真实的动态视觉数据集。因此当需要训练的模型需要更多的数据集时,不妨尝试用Kubric来生成想要的数据集。
参考文献
1.Nikolenko, Sergey I. Synthetic data for deep learning. Springer, 2021.
2.Greff, Klaus, et al. "Kubric: A scalable dataset generator." arXiv preprint arXiv:2203.03570 (2022).
3.Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. Volume rendering of neural implicit surfaces. arXiv preprint arXiv:2106.12052, 2021. 9
4.Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." European conference on computer vision. Springer, Cham, 2020.
5.Dosovitskiy, Alexey, et al. "Flownet: Learning optical flow with convolutional networks." Proceedings of the IEEE international conference on computer vision. 2015.
6.Mayer, Nikolaus, et al. "A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
上一个: 由简入繁探究机器视觉中的数据增强(上)
下一个: 推荐场景训练加速:大规模混合分布式系统
近期文章




 商务合作:business@birentech.com
商务合作:business@birentech.com 业务电话:021-68773133
业务电话:021-68773133

商务合作